Feature Demo: Running SparkSQL Statements in Sequence¶
Welcome to this demo page where we will go trough a huge sparksnake's feature that allows users to enhange their Spark applications by executing multiple predefined SparkSQL in sequence. Let's first see the table overview about it.
| 🚀 Feature | Running multiple SparkSQL statements in sequence |
| 💻 Method | SparkETLManager.run_spark_sql_pipeline() |
| ⚙️ Operation Mode | Available in all operation modes |
SparkETLManager class setup¶
Before we move to the method demonstration, let's import and initialize the SparkETLManager class from sparksnake.manager module. As this feature is presented in the sparksnake's default mode (and so any operation mode can use it too), the class initialization is quite simple.
Importing and initializing the SparkETLManager class
🎬 Demonstration:
![]()
🐍 Code:
# Importing libraries
from sparksnake.manager import SparkETLManager
# Starting the class
spark_manager = SparkETLManager(
mode="default" # or any other operation mode
)
The run_spark_sql_pipeline() method¶
From now on, we will deep dive into the possibilities delivered by the run_spark_sql_pipeline() method. For each new subsection of this page, a different application of the method will be shown with a hands on demo. The idea is to provide a clear view of all possibilities available in the method and to show everything that can be done with it.
If you haven't already taken a look at the method's documentation, take your chance to understand how we will configure its parameters in order to achieve all of our goals. Just to summarize it, when calling the run_spark_sql_pipeline() method we have the following parameters to configure:
spark_sessionto run the SparkSQL statementsspark_sql_pipelineto serve as a Python list with a predefined set of information about the SparkSQL statements to be executed
A key note about the spark_sql_pipeline method argument
As stated on the method's official docs, the spark_sql_pipeline methos argument can be defined as a Python list made by dictionaries, each one with a different execution step. Each of these steps should have at least an integer index that identifies the order of execution and a SparkSQL query.
In summary, the inner dictionaries of the spark_sql_pipeline list should be made with the following keys:
"step"(required): defines the order in wich the given query will be executed"query"(required): a SparkSQL query statement"create_temp_view"(optional, default=True): a boolean flag that leads to the creation of a Spark temporary view after executing the given query"temp_view"(optional, default="auto"): the name of the temporary view created if "create_temp_view" is equal to True. If didn't set, the default value for this key considers the creation of a temp view named "step_N", where "N" is the integer that defines the step.
For more information about this argument, don't forget to check the official docs.
Prelude: defining our application goal¶
Well, to be as objective as possible in this demo, let's consider a scenario where we want to develop a Spark application using only (or mostly) SparkSQL queries for any reason.
Sometimes, handling a bunch of queries can be very difficult, specially if we are talking about given maintenance or including more queries to run between steps. So, with run_spark_sql_pipeline(), the idea is to provide a very clear way to define all the steps needed to run in a Spark application where each step is made by a SparkSQL statement.
So the question is: how can we define this pipeline made of steps? Well, the aforementioned method has a argument called spark_sql_pipeline with this purpose. In this demo, let's consider that we want to define our pipeline with the following steps:
- Step 1: runs a SparkSQL statement that selects attributes from a temporary table previously available
- Step 2: runs a SparkSQL statement that applies a group by operation in another temporary table previously available also
- Step 3: runs a SparkSQL statament that joins data from the temp table fromstep 1 with the temp table from step 2 to return a final Spark DataFrame
For step 1, let's consider the orders dataset with the desired output:
+--------------------------------+------------+-----------------+
|order_id |order_status|order_purchase_ts|
+--------------------------------+------------+-----------------+
|e481f51cbdc54678b7cc49136f2d6af7|delivered |02/10/2017 10:56 |
|53cdb2fc8bc7dce0b6741e2150273451|delivered |24/07/2018 20:41 |
|47770eb9100c2d0c44946d9cf07ec65d|delivered |08/08/2018 08:38 |
|949d5b44dbf5de918fe9c16f97b45f8a|delivered |18/11/2017 19:28 |
|ad21c59c0840e6cb83a9ceb5573f8159|delivered |13/02/2018 21:18 |
+--------------------------------+------------+-----------------+
only showing top 5 rows
For step 2, we will consider the payments dataset with the desired output:
+--------------------------------+-----------------+
|order_id |sum_payment_value|
+--------------------------------+-----------------+
|bb2d7e3141540afc268df7ef6580fc75|37.15 |
|85be7c94bcd3f908fc877157ee21f755|72.75 |
|8ca5bdac5ebe8f2d6fc9171d5ebc906a|189.08 |
|54066aeaaf3ac32e7bb6e45aa3bf65e4|148.06 |
|5db54d41d5ebd6d76cb69223355601f5|136.26 |
+--------------------------------+-----------------+
An then, for step 3 we need to join both results from steps 1 and 2 in order to achieve the following output:
+--------------------------------+------------+-----------------+-----------------+
|order_id |order_status|order_purchase_ts|sum_payment_value|
+--------------------------------+------------+-----------------+-----------------+
|e481f51cbdc54678b7cc49136f2d6af7|delivered |02/10/2017 10:56 |38.71 |
|53cdb2fc8bc7dce0b6741e2150273451|delivered |24/07/2018 20:41 |141.46 |
|47770eb9100c2d0c44946d9cf07ec65d|delivered |08/08/2018 08:38 |179.12 |
|949d5b44dbf5de918fe9c16f97b45f8a|delivered |18/11/2017 19:28 |72.2 |
|ad21c59c0840e6cb83a9ceb5573f8159|delivered |13/02/2018 21:18 |28.62 |
+--------------------------------+------------+-----------------+-----------------+
So now let's get our hands dirty!
Running a Spark application with SparkSQL queries¶
For our pipeline steps definition, let's start by building a Python list where each element will have a Python dictionary with all information required to run our SparkSQL queries.
Defining the spark_sql_pipeline argument
🎬 Demonstration:
🐍 Code:
# Defining a list with all SparkSQL steps to be executed
spark_sql_pipeline = [
{
"step": 1,
"query": """
SELECT
order_id,
order_status,
order_purchase_ts
FROM tbl_orders
"""
},
{
"step": 2,
"query": """
SELECT
order_id,
sum(payment_value) AS sum_payment_value
FROM tbl_payments
GROUP BY order_id
"""
},
{
"step": 3,
"query": """
SELECT
step_1.order_id,
step_1.order_status,
step_1.order_purchase_ts,
step_2.sum_payment_value
FROM step_1
LEFT JOIN step_2
ON step_1.order_id = step_2.order_id
"""
}
]
In this moment, I ask you to take a deep look at the spark_sql_pipeline variable defined above. Do you see now how it works? It's an easy and efficient way to put together multiple SparkSQL queries that will run in a sequence defined by the step index provided in each inner dictionary. There are many possibilities to combine this approach with new ideas, such as:
- Putting the queries in .sql files and reading them in a application script that calls the
run_spark_sql_pipeline()method - Defining a JSON file with all the steps and just reading it in the application scripts that calls the method
- etc...
Now that we have built our "pipeline", let's just call the method and see the result.
Running the pipeline
🎬 Demonstration:
🐍 Code:
# Defining a list with all SparkSQL steps to be executed
spark_sql_pipeline = [
{
"step": 1,
"query": """
SELECT
order_id,
order_status,
order_purchase_ts
FROM tbl_orders
"""
},
{
"step": 2,
"query": """
SELECT
order_id,
sum(payment_value) AS sum_payment_value
FROM tbl_payments
GROUP BY order_id
"""
},
{
"step": 3,
"query": """
SELECT
step_1.order_id,
step_1.order_status,
step_1.order_purchase_ts,
step_2.sum_payment_value
FROM step_1
LEFT JOIN step_2
ON step_1.order_id = step_2.order_id
"""
}
]
# Running the SparkSQL pipeline
df_prep = run_spark_sql_pipeline(
spark_session=spark_manager.spark,
spark_sql_pipeline=spark_sql_pipeline
)
# Checking the result
df_prep.show(5, truncate=False)
And that's what happened after the method call:
- It was applied a sort operation on the
spark_sql_pipelinelist to consolidate the order of the queries to be executed based on the step index provided - Each query was executed and a temporary view with results of each step was created
- The last query was executed and a final DataFrame object was returned
Running queries from .sql files stored in project directory¶
Well, in this bonus section, we will show roughly the same application of the run_spark_sql_pipeline() method but changing things a little bit: this time, rather than putting all the SparkSQL queries directly in the spark_sql_pipeline argument, we will store a different .sql file in our project directory to improve the organization of our Spark application.
With this approach, users can have different sql files for different queries, allowing them to improve the code maintenance, to change business rules faster and to have a more organized structure in application scripts.
So, let's leverage the same use case where we have a transformation query for orders dataset, another one for payments dataset and a third one joining the results of the previous two. We will put all .sql files in a sql/ folder.
Preparing .sql files with SparkSQL queries
🎬 Demonstration:
🐍 Code:
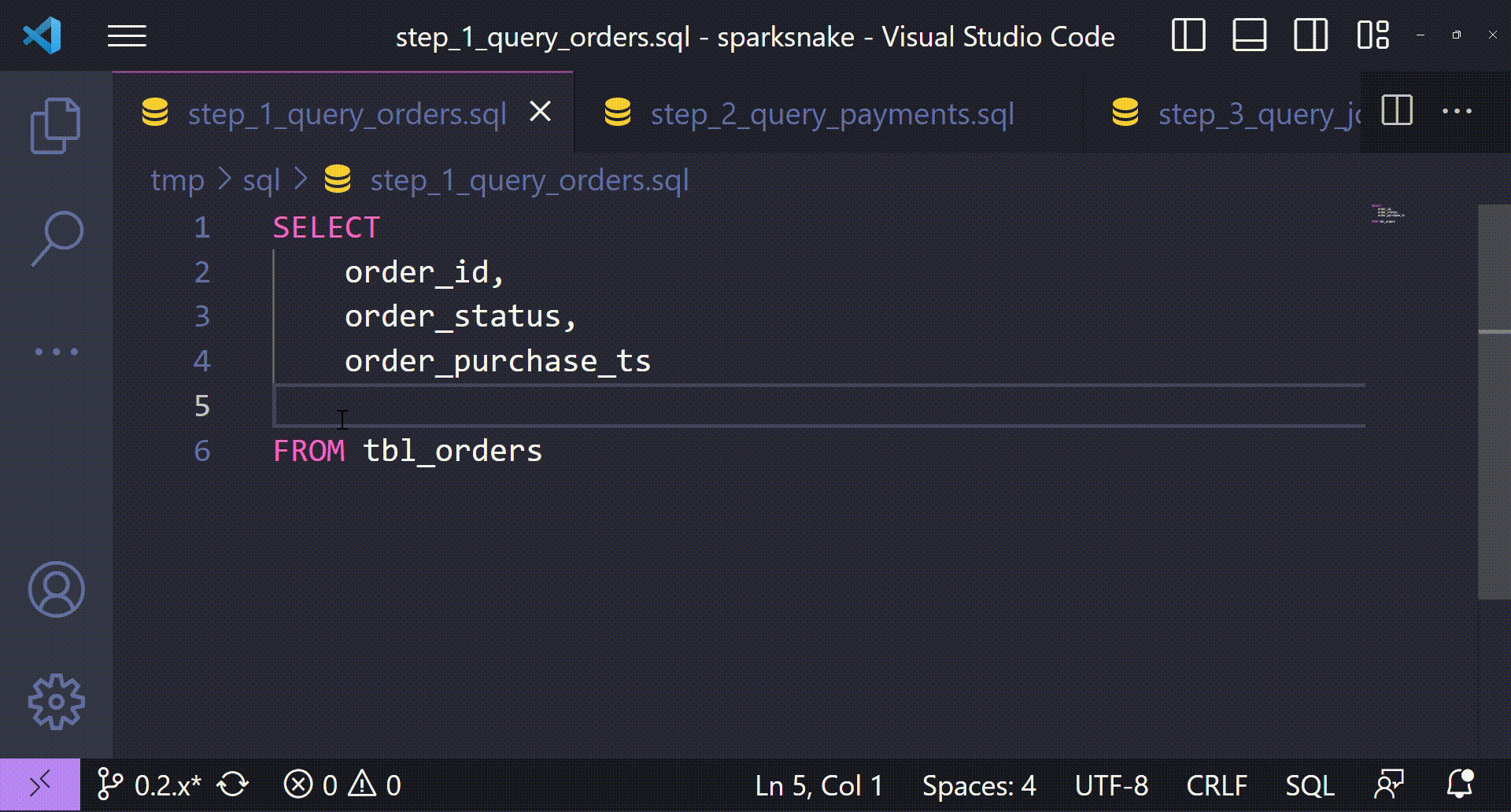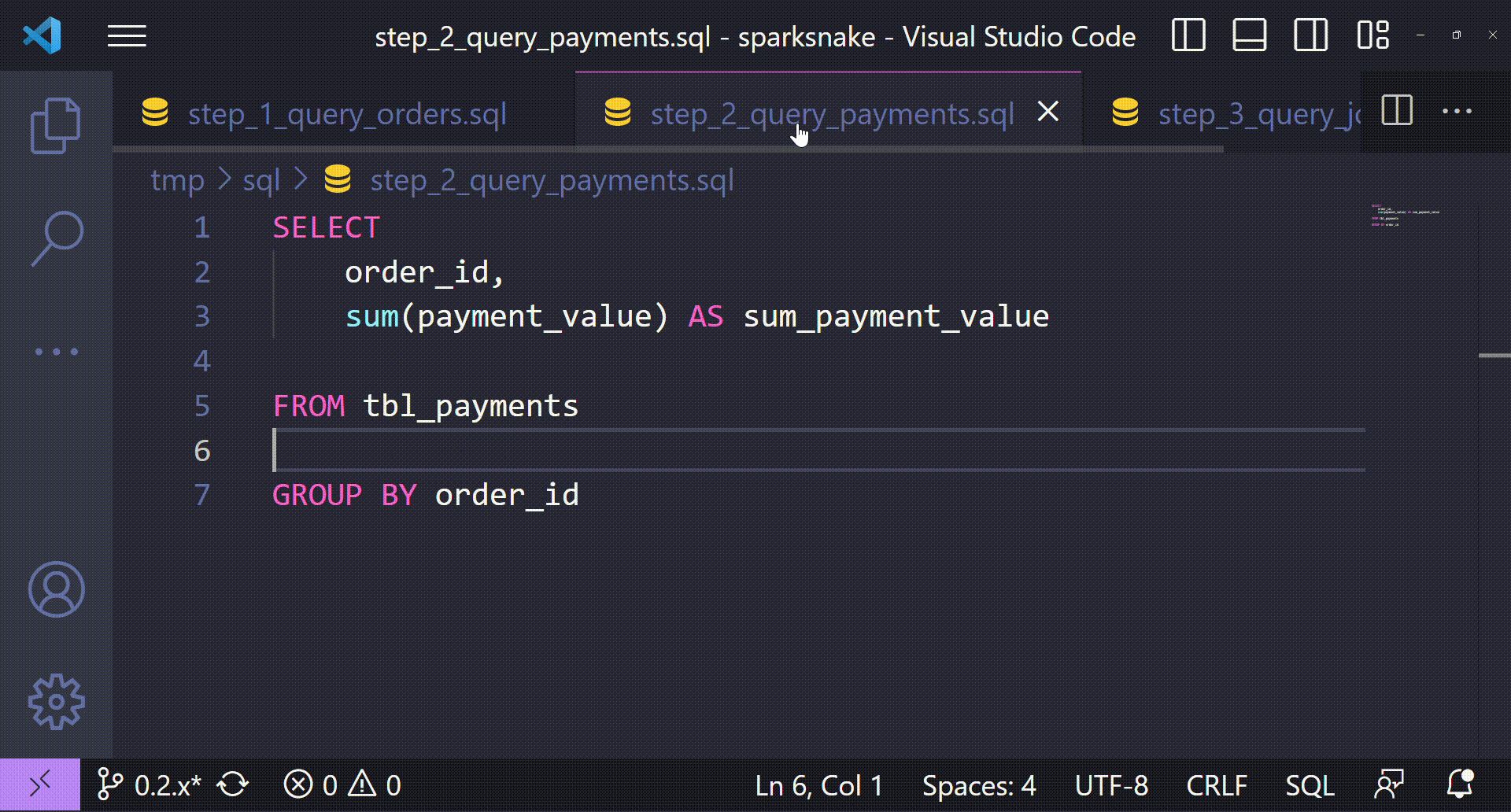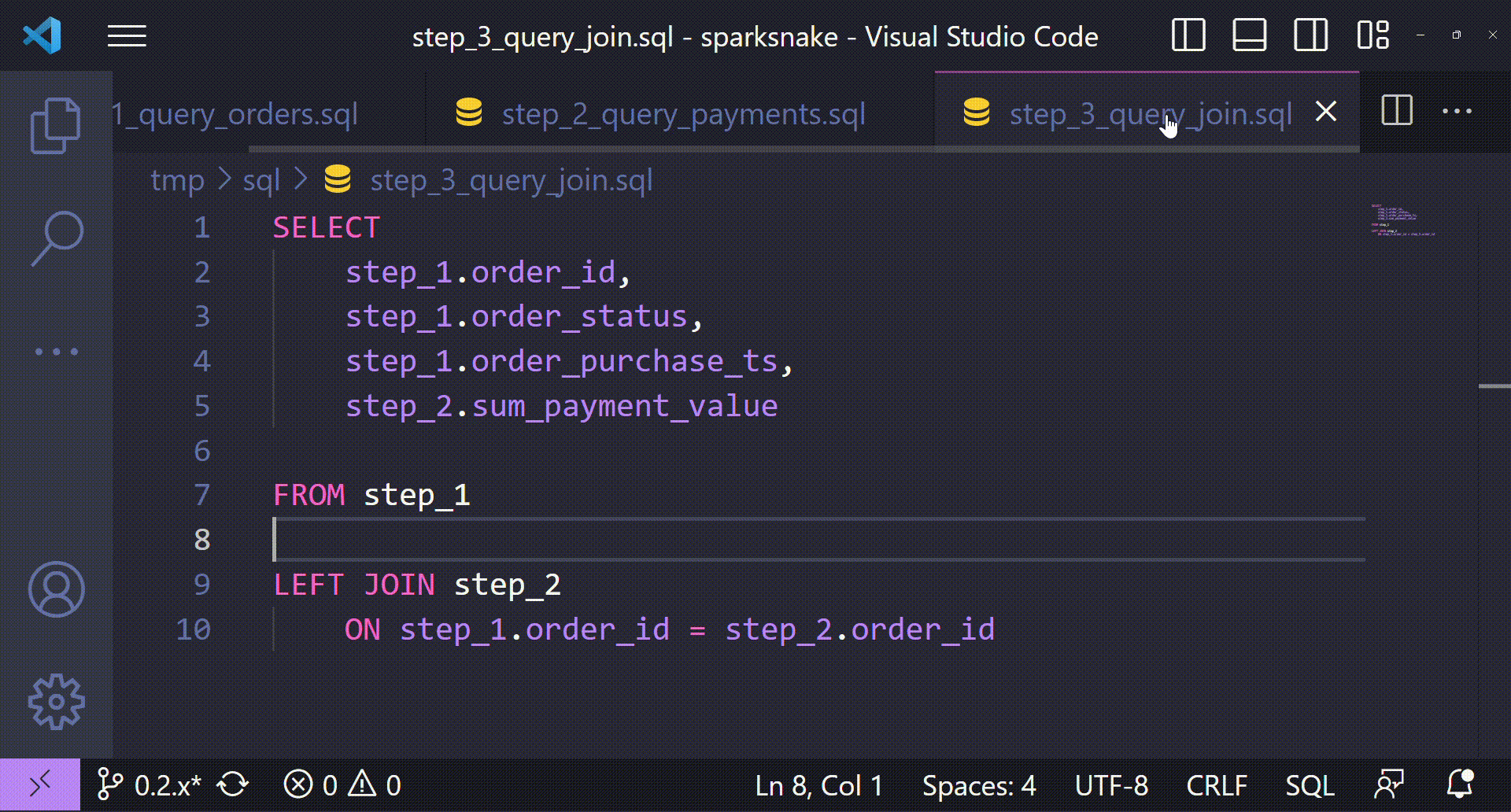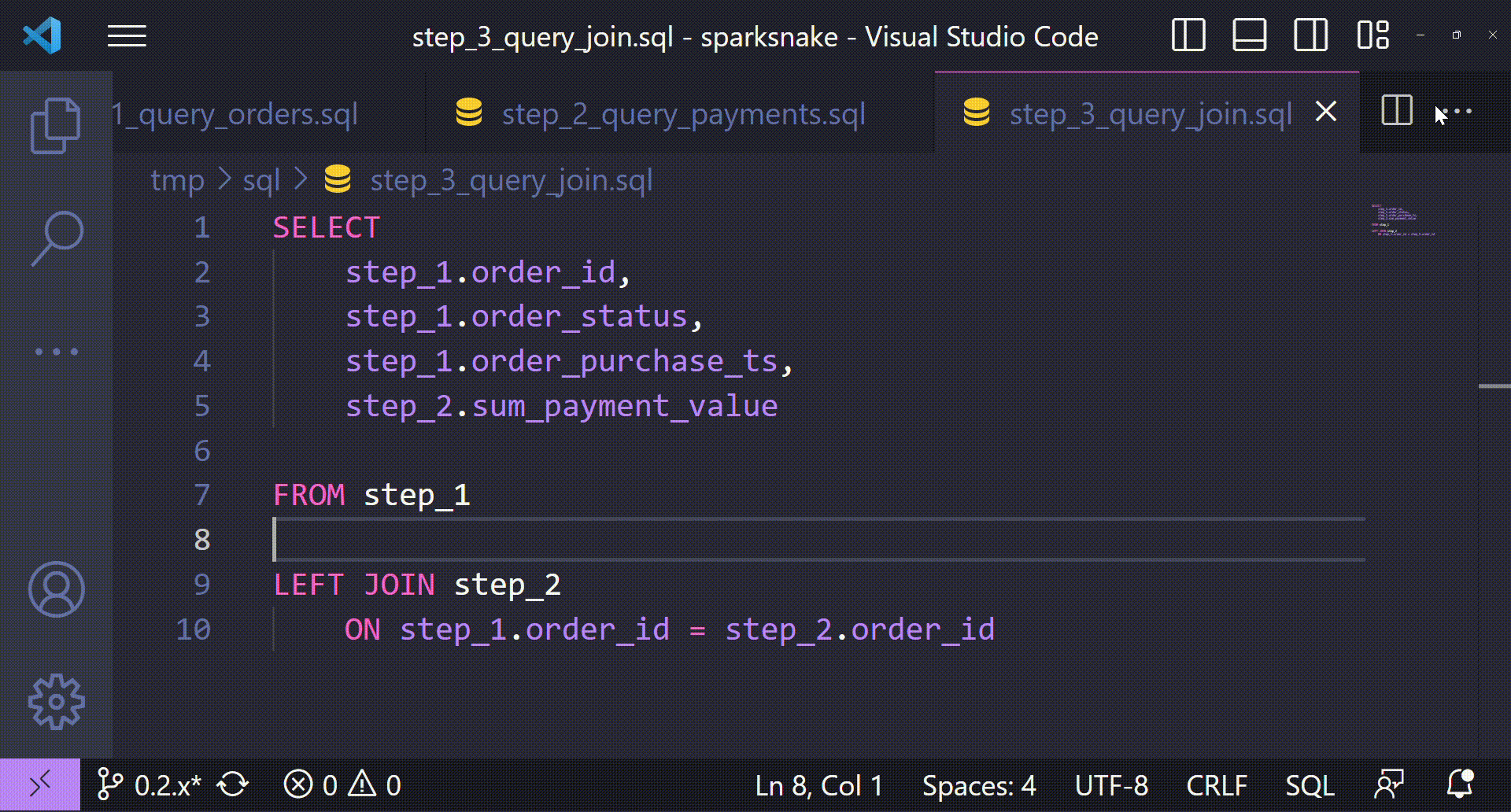
step_1_query_orders.sql:
SELECT
order_id,
order_status,
order_purchase_ts
FROM tbl_orders
step_2_query_payments.sql:
SELECT
order_id,
sum(payment_value) AS sum_payment_value
FROM tbl_payments
GROUP BY order_id
step_3_query_join.sql:
SELECT
step_1.order_id,
step_1.order_status,
step_1.order_purchase_ts,
step_2.sum_payment_value
FROM step_1
LEFT JOIN step_2
ON step_1.order_id = step_2.order_id
So, after putting all the queries in different files in a single folder, we can now define our spark_sql_pipeline variable where the inner dictionaries won't have the query string in the "query" key anymore. Now, we will read the respective .sql file using any file read method available in Python. Let's see how it goes.
Defining the spark_sql_pipeline list argument reading queries from external .sql files
🎬 Demonstration:
🐍 Code:
# Importing auxiliar libraries
from pathlib import Path
# Defining a list with all SparkSQL steps to be executed
spark_sql_pipeline = [
{
"step": 1,
"query": Path("../../../sql/step_1_query_orders.sql").read_text()
},
{
"step": 2,
"query": Path("../../../sql/step_2_query_payments.sql").read_text()
},
{
"step": 3,
"query": Path("../../../sql/step_3_query_join.sql").read_text()
}
]
Well, it is much more consise, isn't? With this approach, the spark_sql_pipeline list doesn't need to have a bunch of complex and long-text SQL queries. It's easier to take query of queries in separate files.
And finally, we just need to execute our run_spark_sql_pipeline() method and see if we get the same result as before.
Running the pipeline with this different query organization approach
🎬 Demonstration:
🐍 Code:
# Importing auxiliar libraries
from pathlib import Path
# Defining a list with all SparkSQL steps to be executed
spark_sql_pipeline = [
{
"step": 1,
"query": Path("../../../sql/step_1_query_orders.sql").read_text()
},
{
"step": 2,
"query": Path("../../../sql/step_2_query_payments.sql").read_text()
},
{
"step": 3,
"query": Path("../../../sql/step_3_query_join.sql").read_text()
}
]
# Running the pipeline
df_prep = spark_manager.run_spark_sql_pipeline(
spark_session=spark_manager.spark,
spark_sql_pipeline=spark_sql_pipeline
)
# Showing a sample
df_prep.show(5, truncate=False)
And that's it for the run_spark_sql_pipeline() method demo! I hope this one can be a good way to enrich your Spark applications that needs to run multiple SparkSQL queries sequentially!