Usage Journey: Enhancing Glue Jobs Development with sparksnake¶
Welcome to the sparksnake library feature demos page with its operation mode focused on Spark applications designed to be used and deployed as Glue jobs on AWS! Fasten your seat belts and let's go code!
Initial Setup¶
To provide an extremely detailed consumption journey, this initial section will include a highly didactic step by step on using the sparksnake library for the first time ever. For users who have little to none experience developing Python code, this is a really nice beginning section.
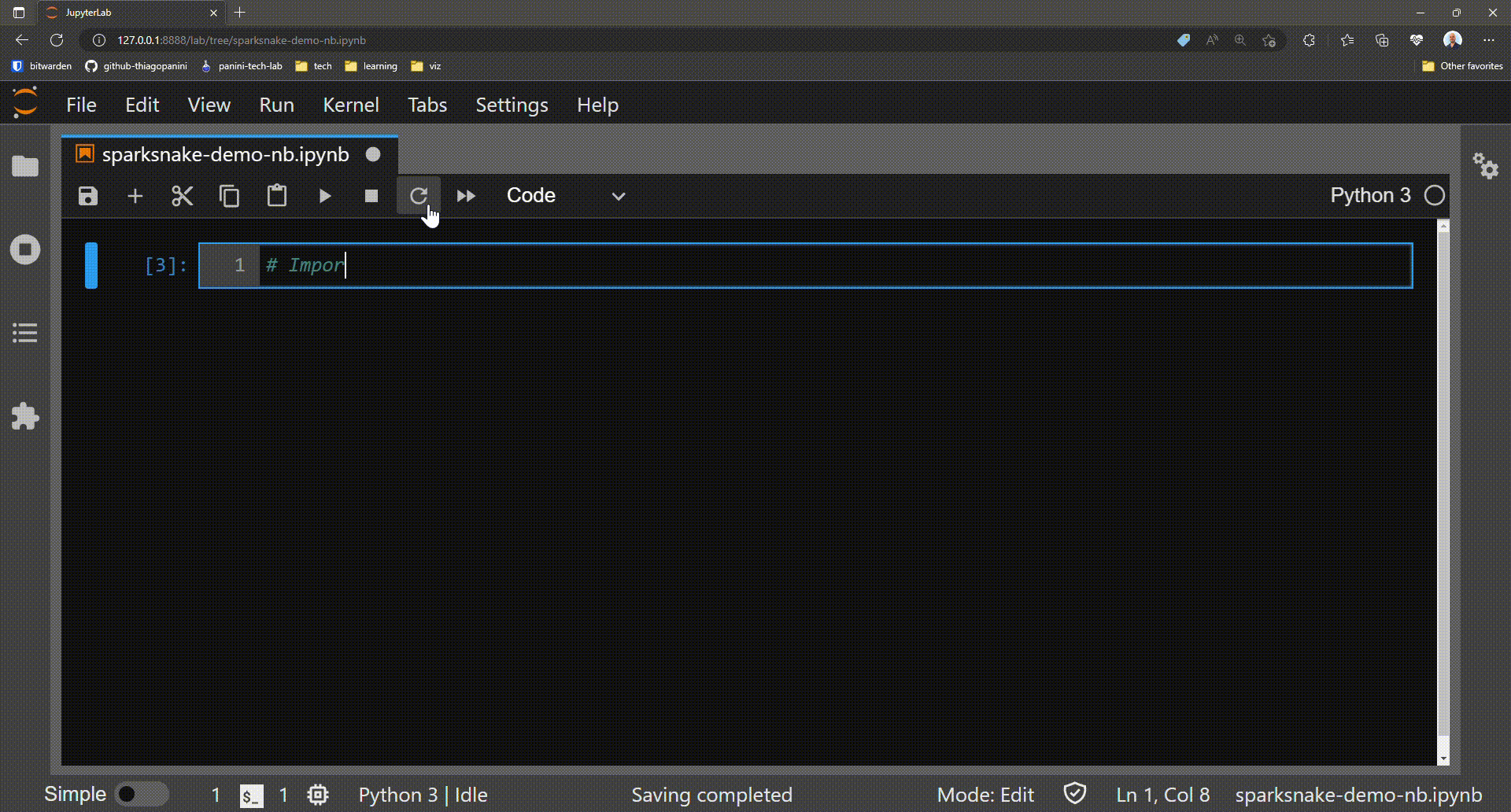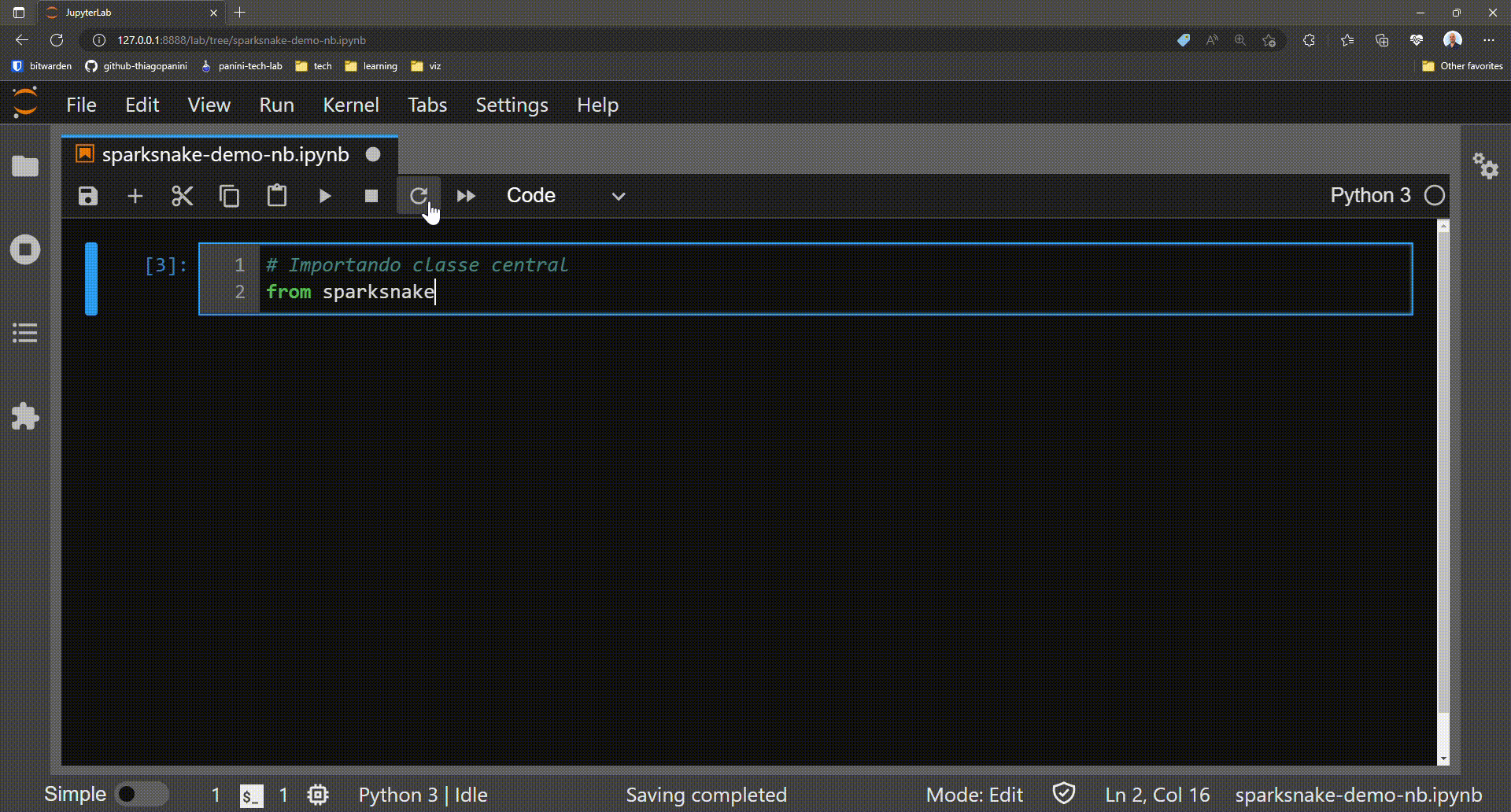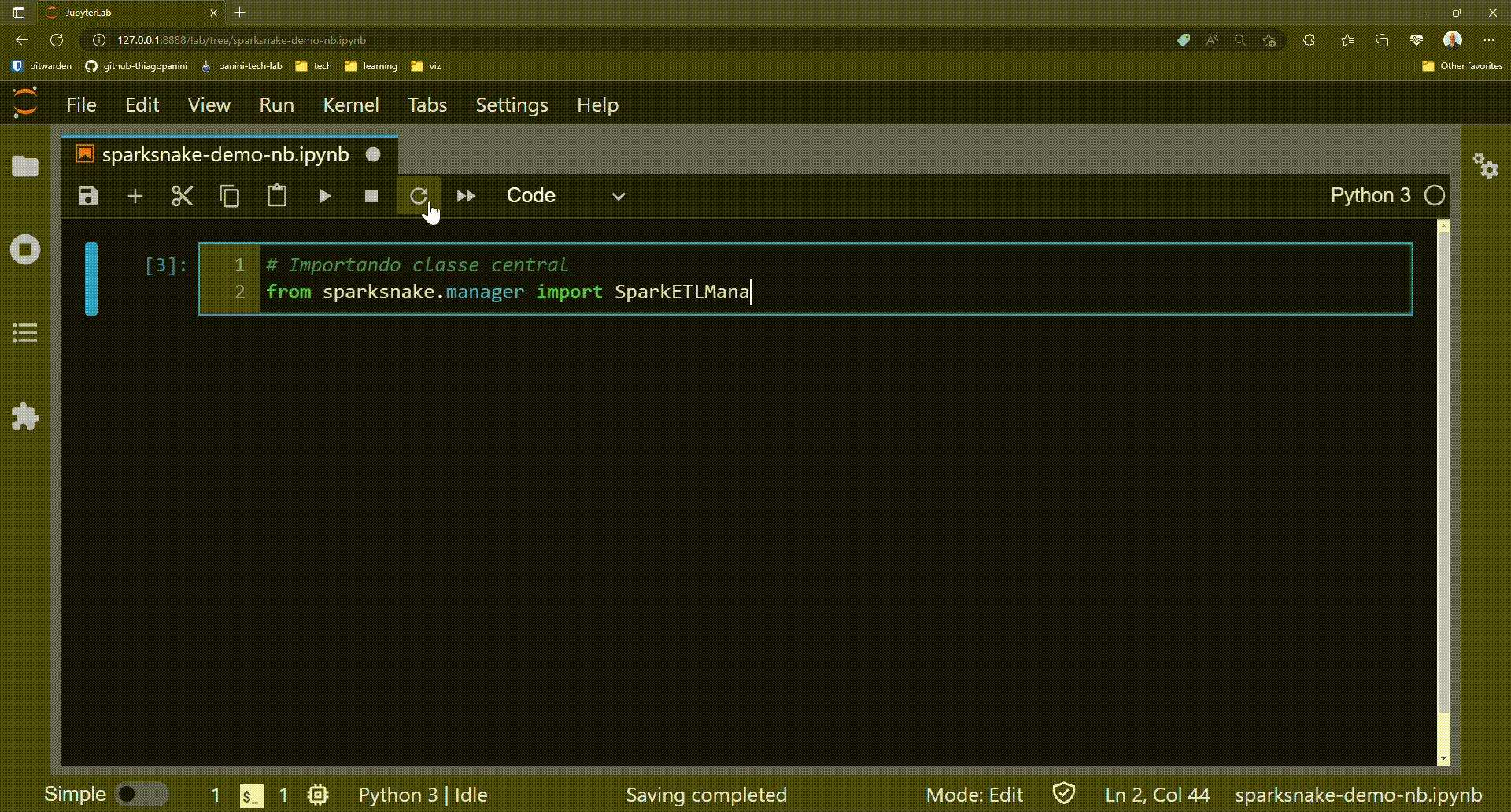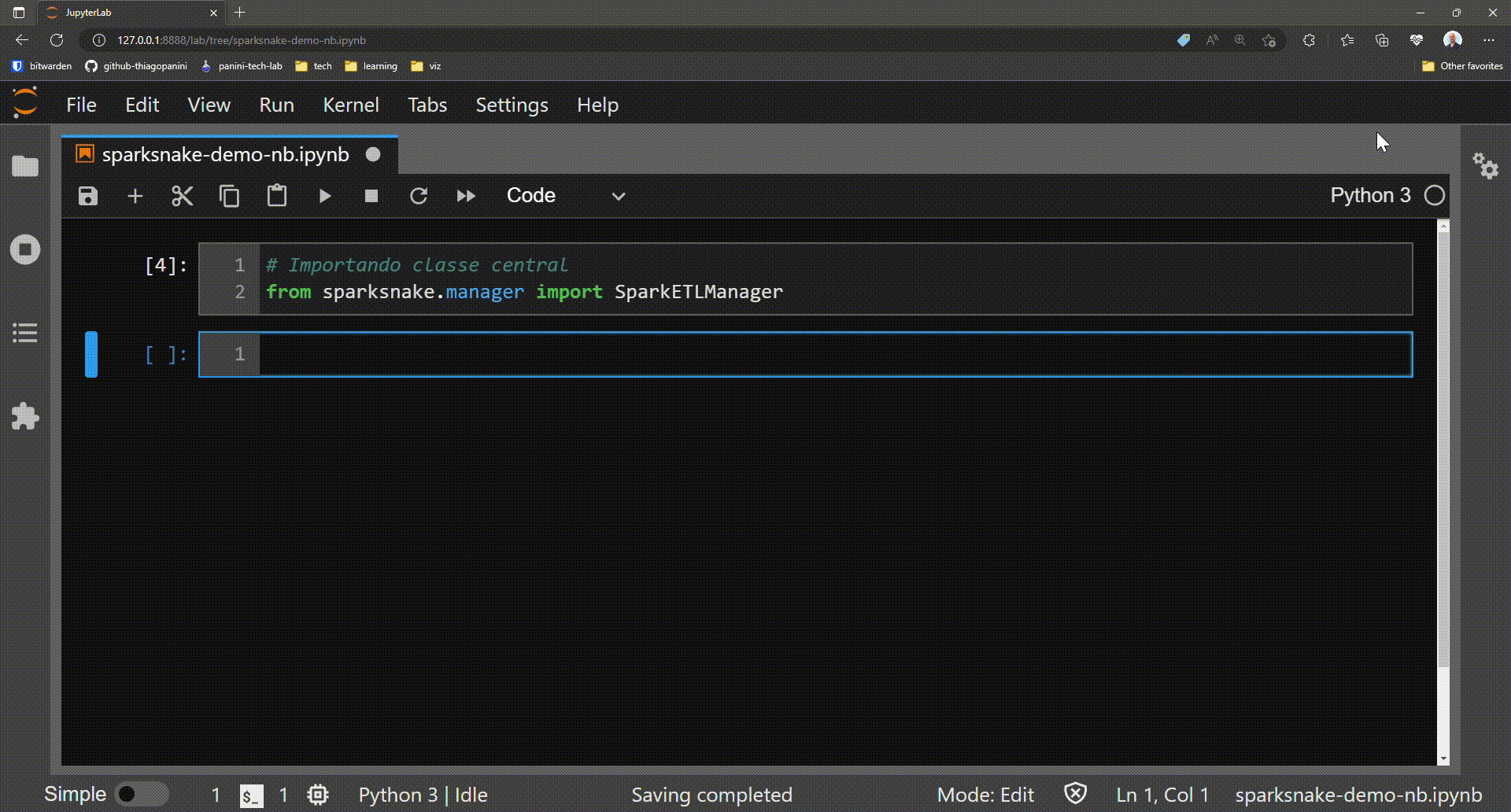
The first step in this journey goes through importing the library's main class that acts as a central point for all existing functionality. This is the class SparkETLManager present in the module manager.
Importing SparkETLManager class on application script
Next, as a prerequisite for initializing a class object for creating Glue jobs on AWS, the user must define two extremely important attributes:
argv_list: List of arguments/parameters used in the Glue job.data_dict: Dictionary containing a mapping of the sources on the data catalog to be read in the Glue job.
The attributes argv_list and data_dict are requirements present in the class GlueJobManager, which in turn is the sparksnake library class created to centralize specific functionality present in the AWS Glue service. Since the journey exemplified here considers this scenario, then the central class SparkETLManager needs to receive the two mandatory attributes so that inheritance between classes can occur on the proper way.
In order for the user to feel extremely comfortable in this specific journey of using glue-linked functionality, examples of defining the attributes will be provided below.
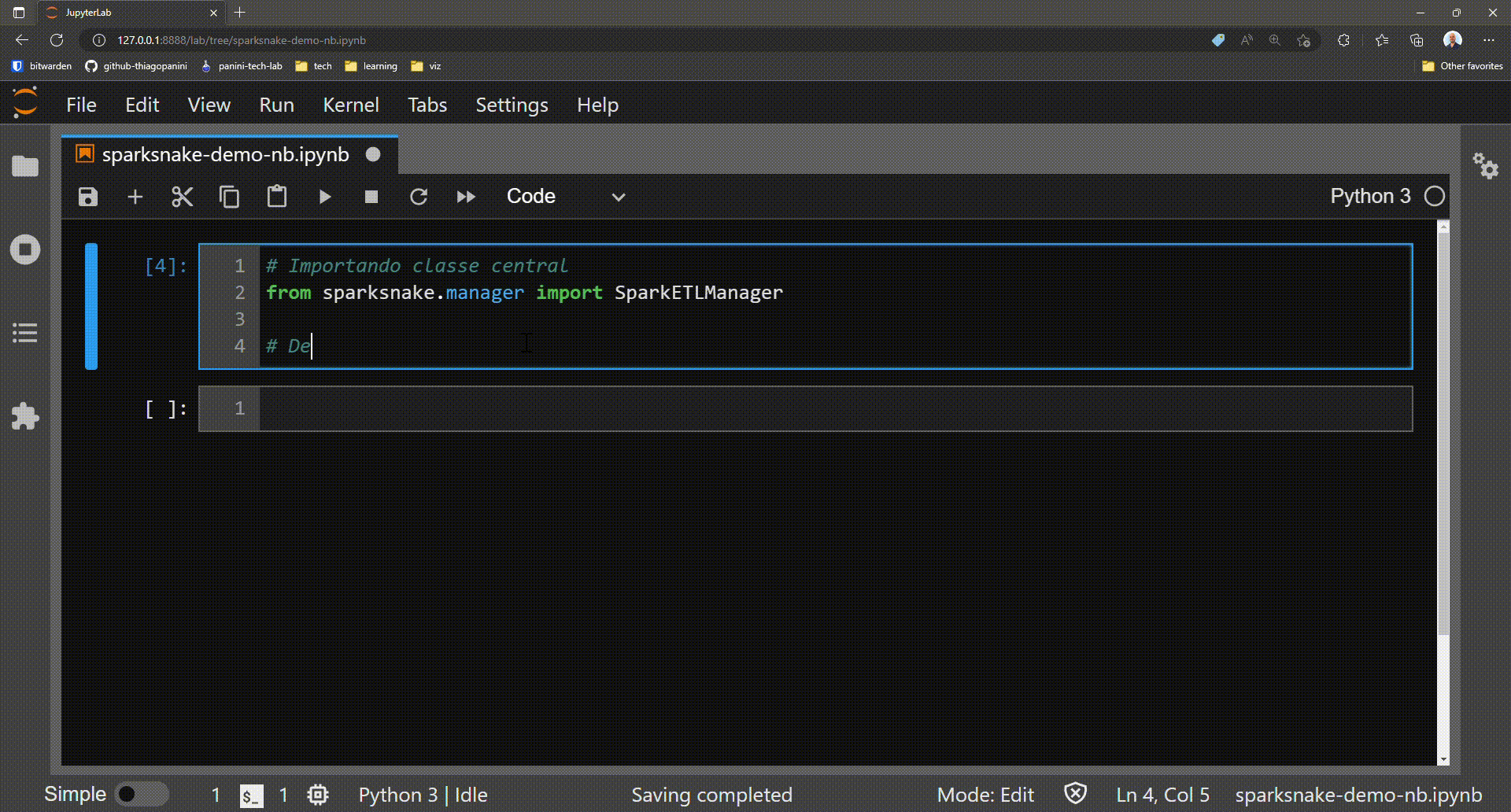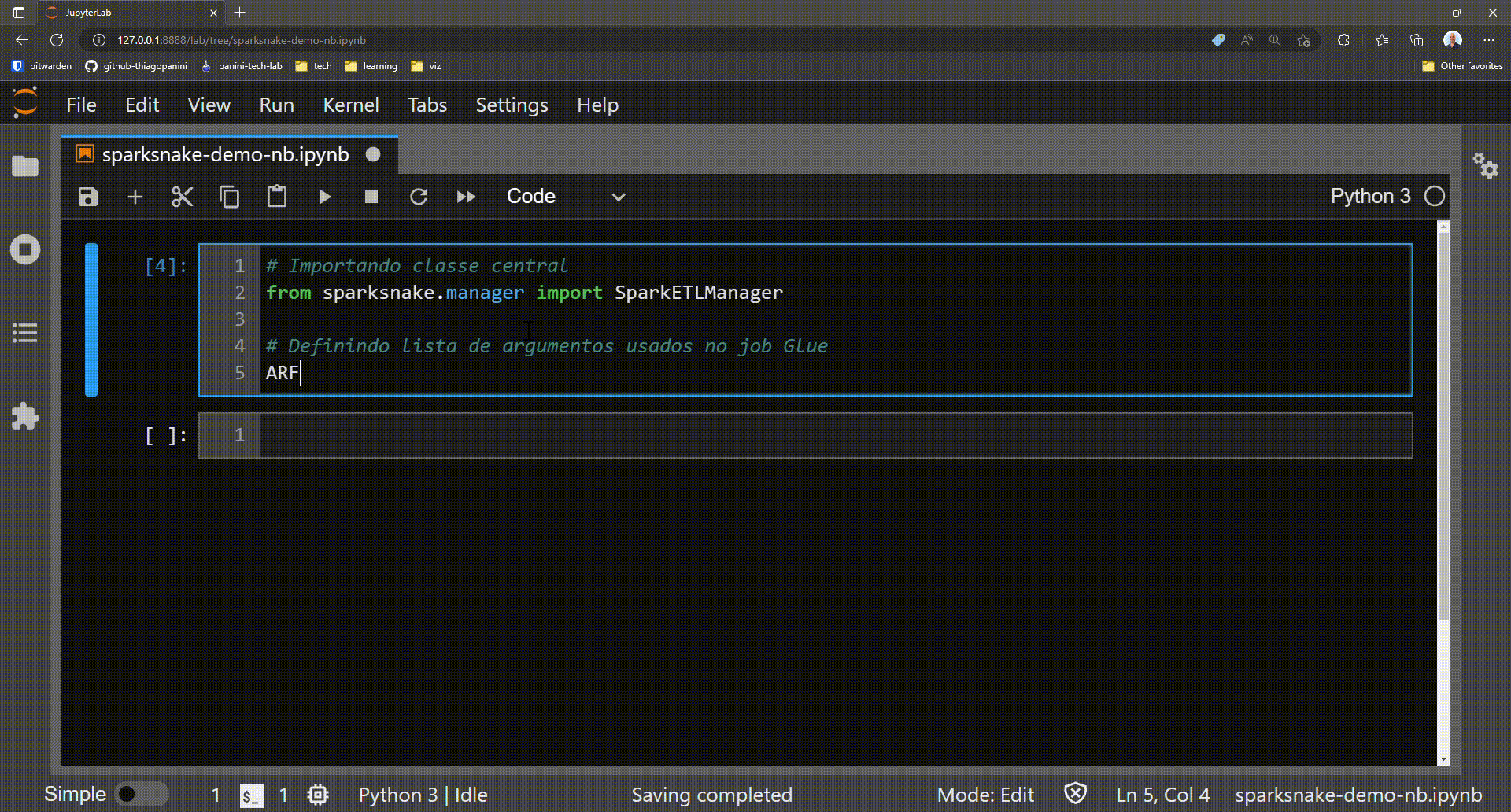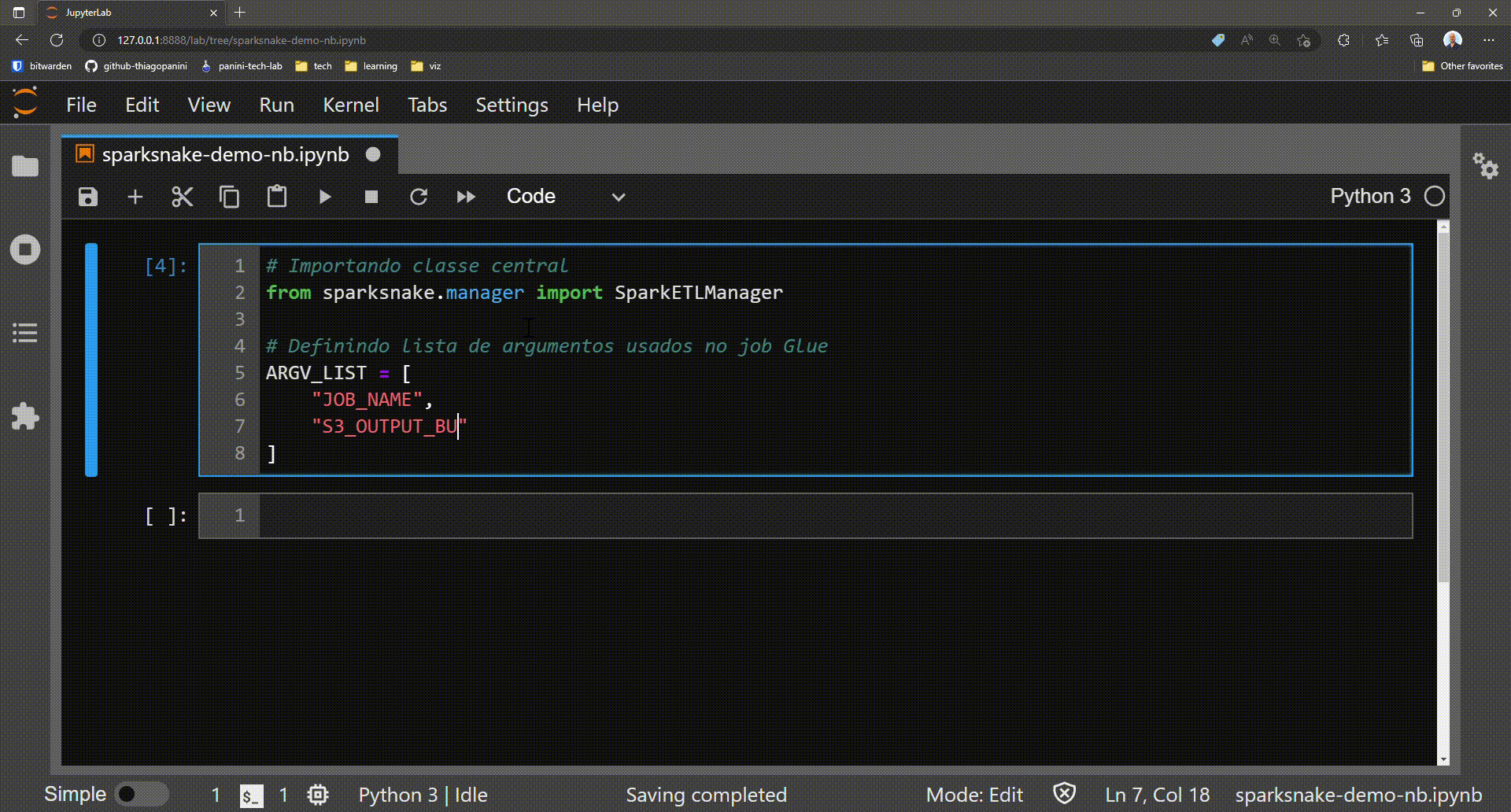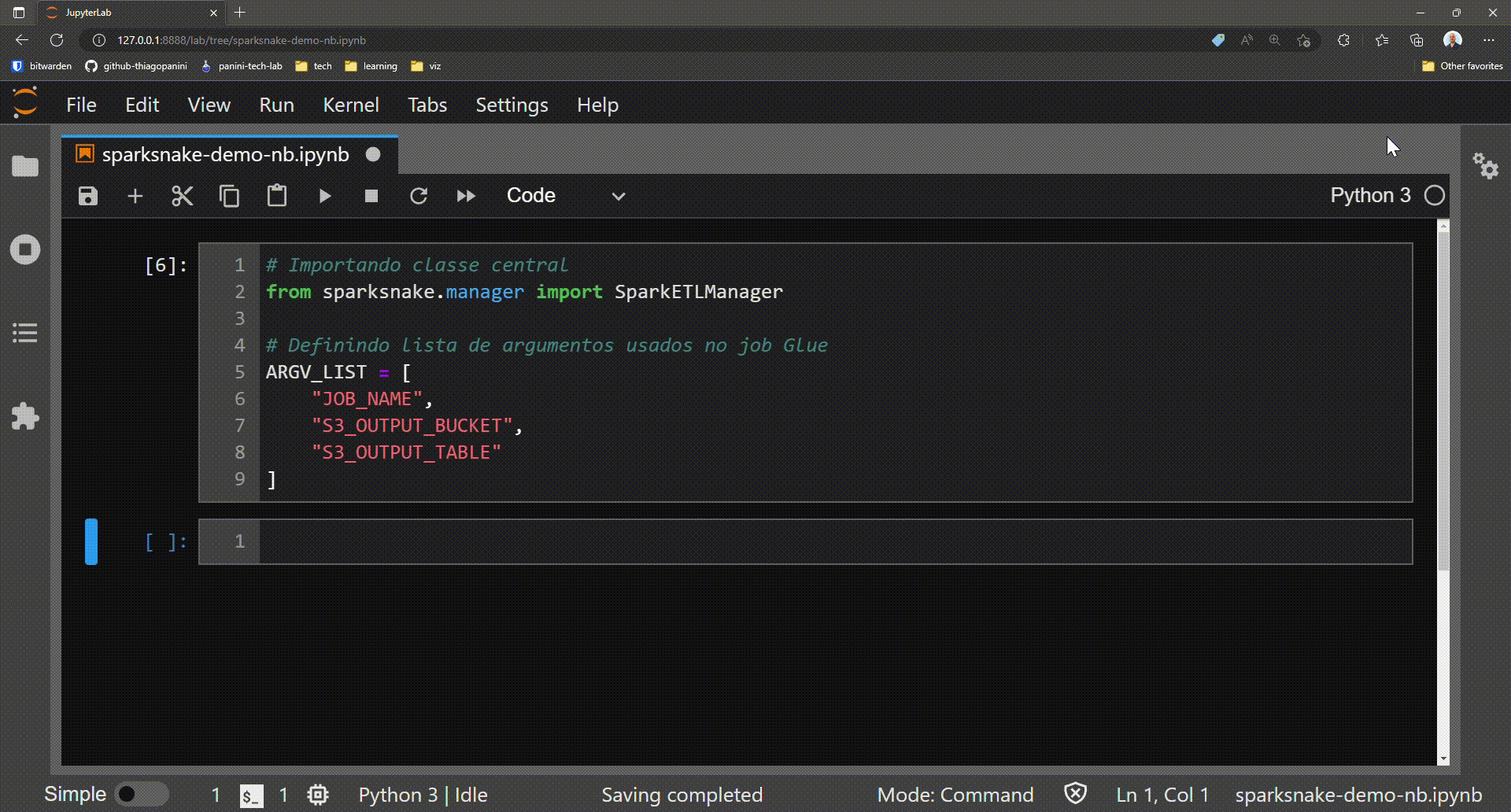
Defining variable ARGV_LIST containing job arguments
About the job argument list
The elements defined in the ARGV_LIST variable provided as an example necessarily need to be exactly the same as the arguments configured for the job. In other words, if the user is using some IaC tool (Terraform or CloudFormation, for example) and in its definition the user declare some job parameters, then these same arguments must be contained in the ARGV_LIST variable.
If arguments or parameters are configured for the job (directly on the console or using an IaC tool) and they are not contained in the ARGV_LIST variable, then Glue will return an error when initializing a job.
Defining DATA_DICT variable to map job data sources
About a job's source mapping dictionary
The great idea about defining a source mapping dictionary as an attribute of sparksnake classes is to provide a single, centralized location so that users can coordinate all the particularities of the sources used in their job using one variable.
This means that anyone who needs to observe the source code of a job created in this form can easily understand details about the sources early in the script, making troubleshooting and possible scope changes easier.
For more details on specificities involving variable definition, see the official documentation of the SparkETLManager class.
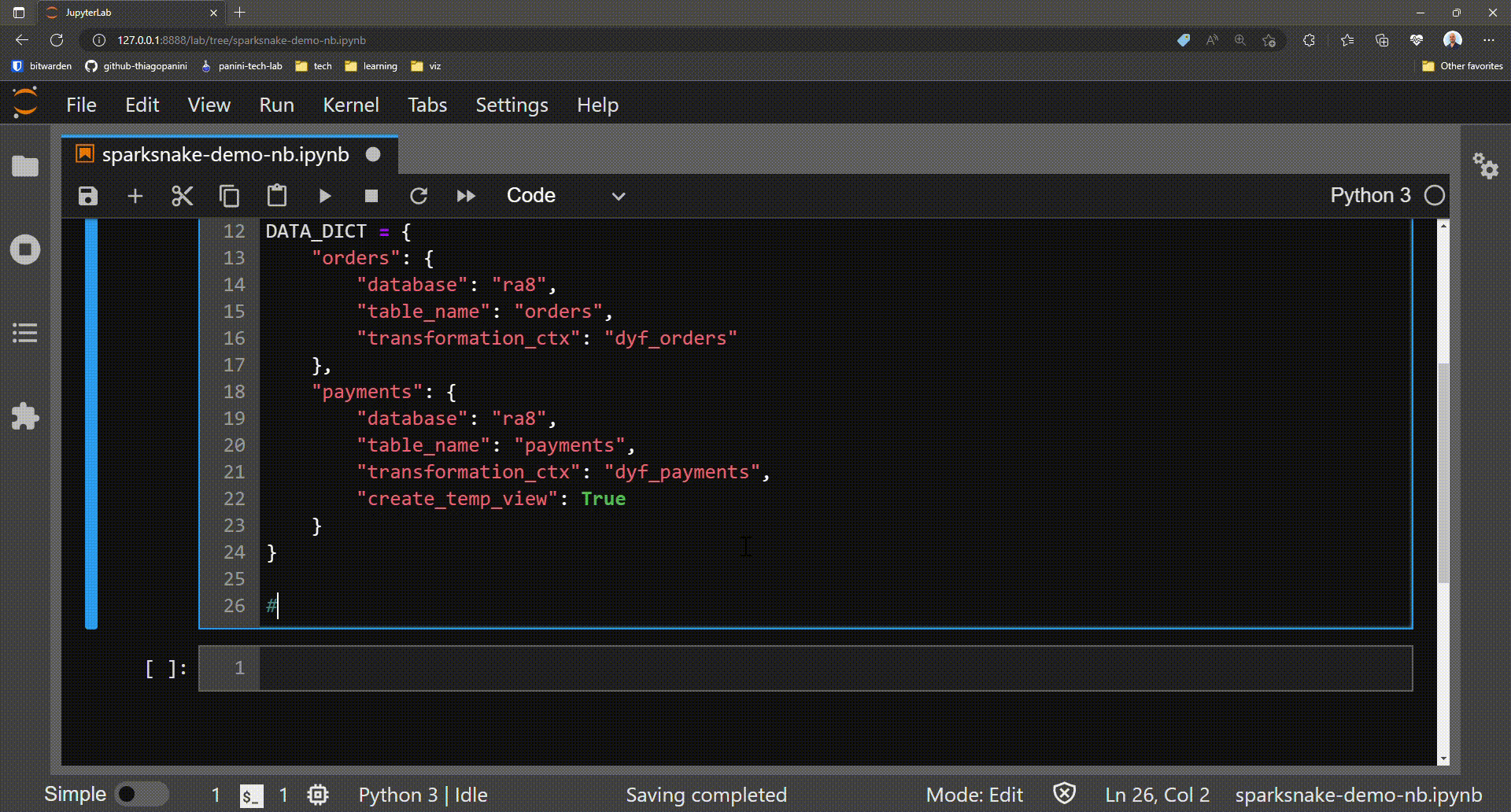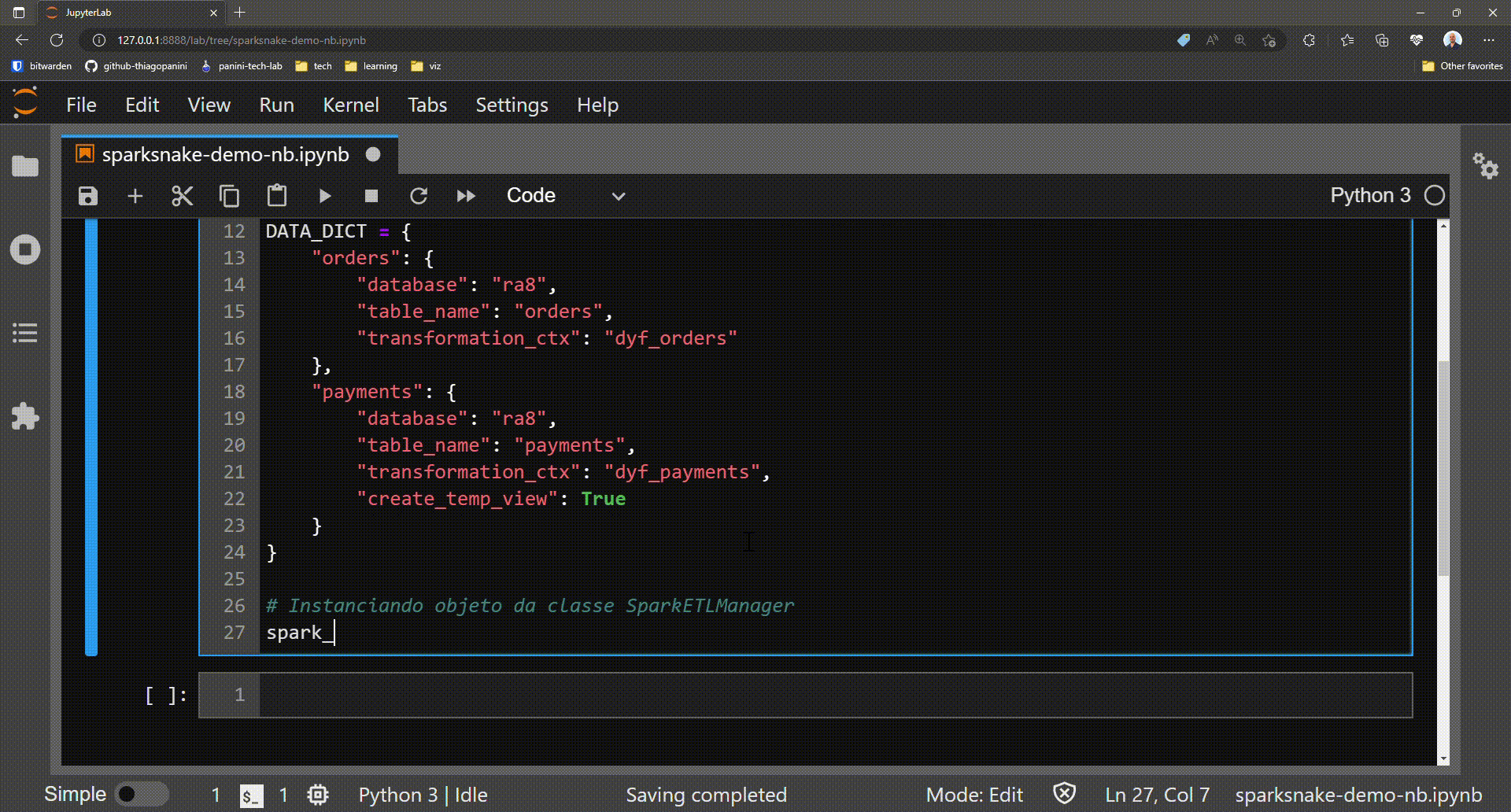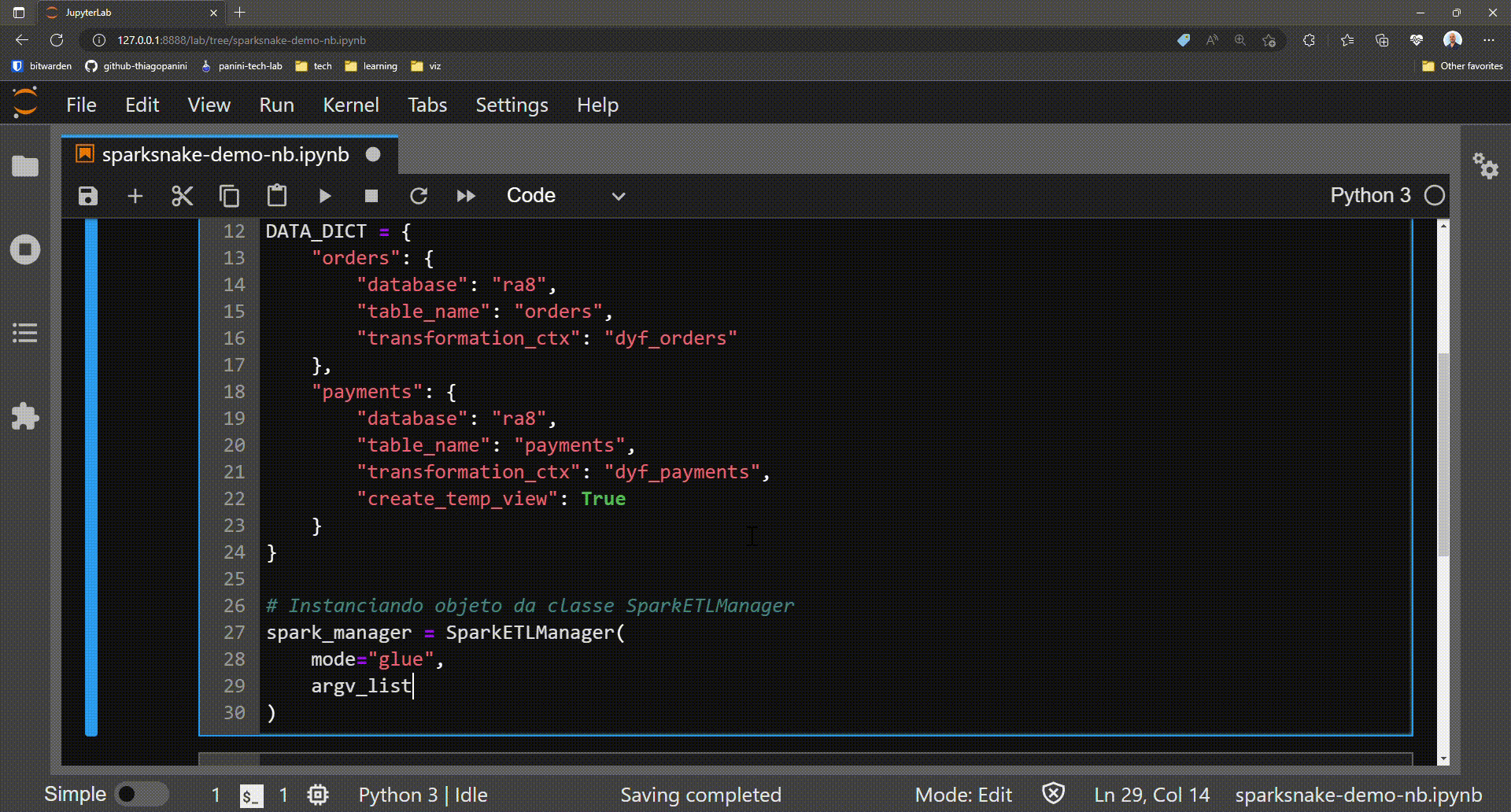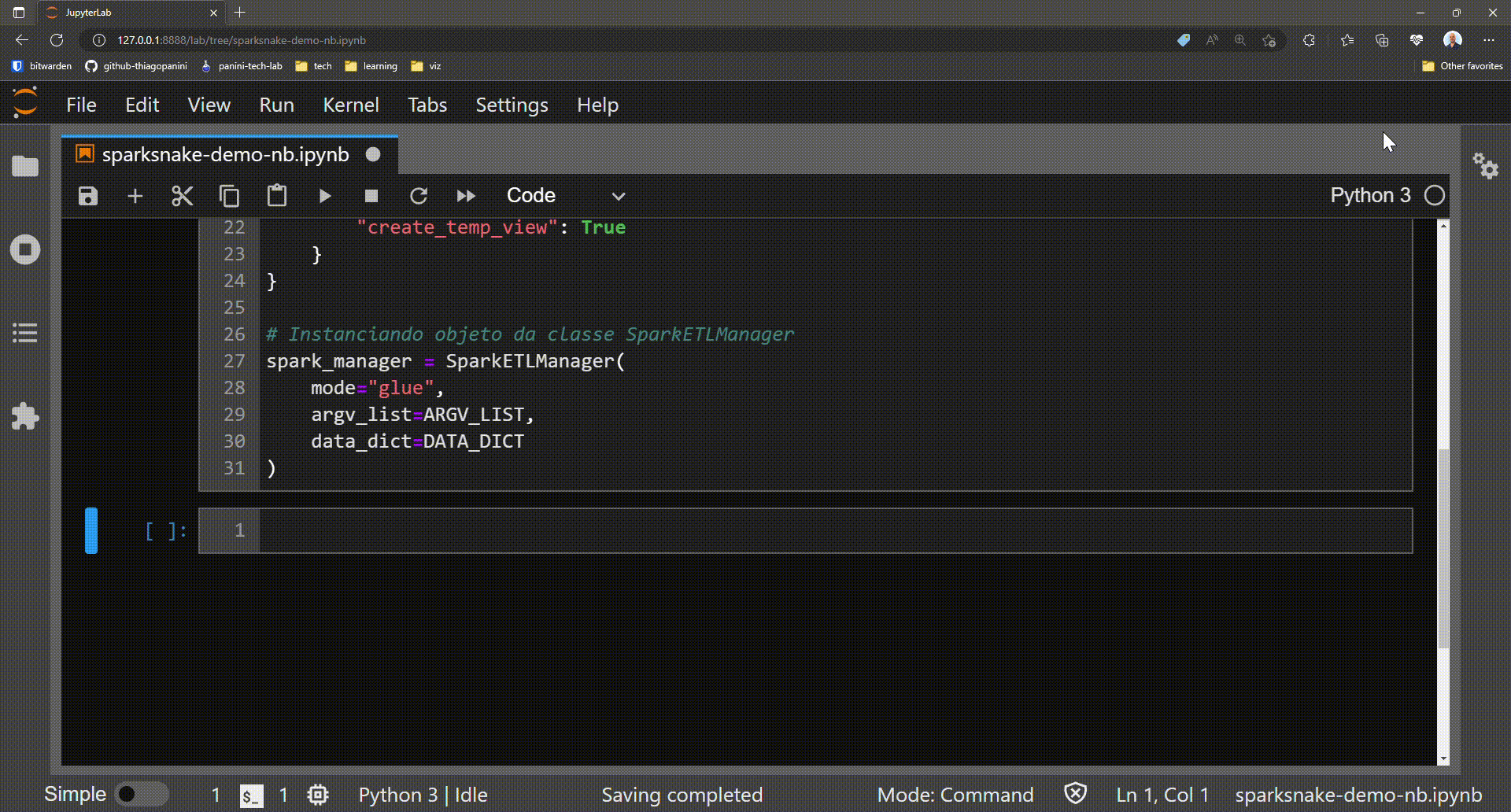
Finally, an object of the SparkETLManager class can be obtained.
Obtaining an object from the class SparkETLManager
 From now on, demonstrations on some of the class's key features will be provided to users. Everything takes place from
From now on, demonstrations on some of the class's key features will be provided to users. Everything takes place from spark_manager object as a way for calling methods and attributes that handle the most common operations find on Glue jobs.
Initializing a Glue Job¶
After the initial script setup, the subsequent stesp of building the application involves initializing a Glue job and obtaining all of its required elements.
Remember glueContext, SparkContext e session? With the init_job() method it's possible to get all of them as class attributes with a single line of code.
Initializing and getting all the elements required by a Glue job
 Demonstration:
Demonstration:
 Advantages and benefits:
Advantages and benefits:
- Obtaining all the elements required to run a Glue job
- Automatic association of the elements as class attributes (see optional demo)
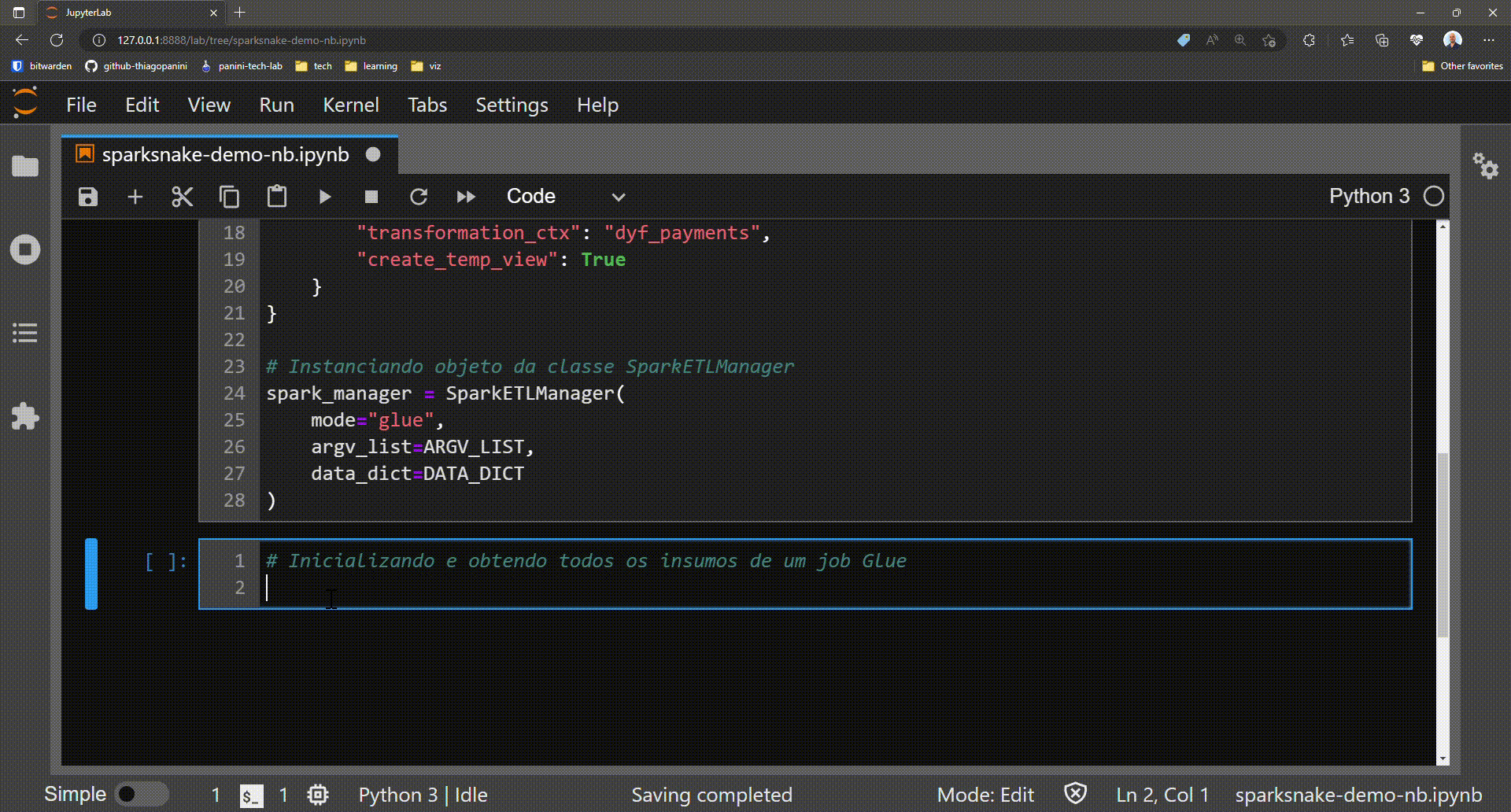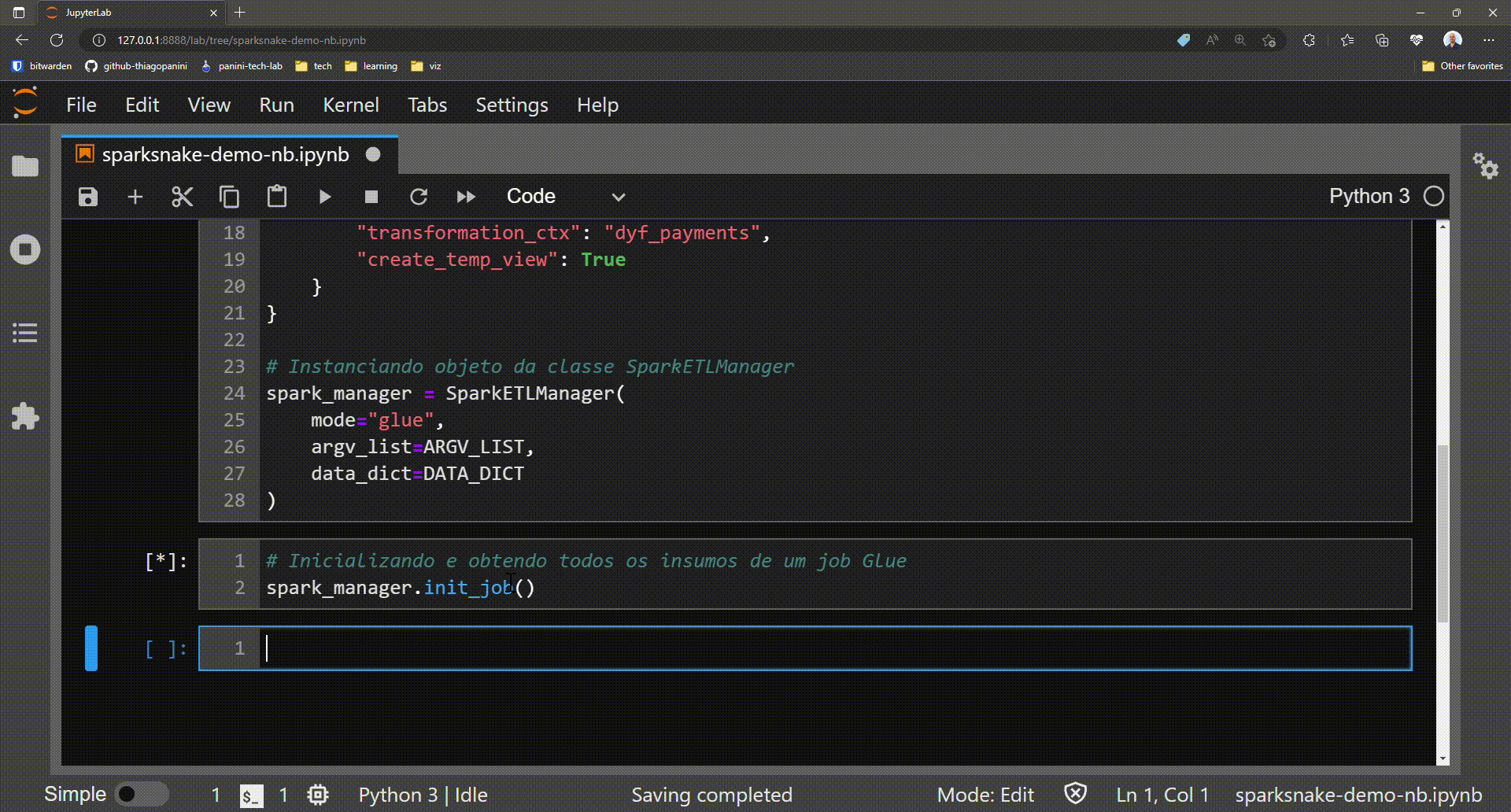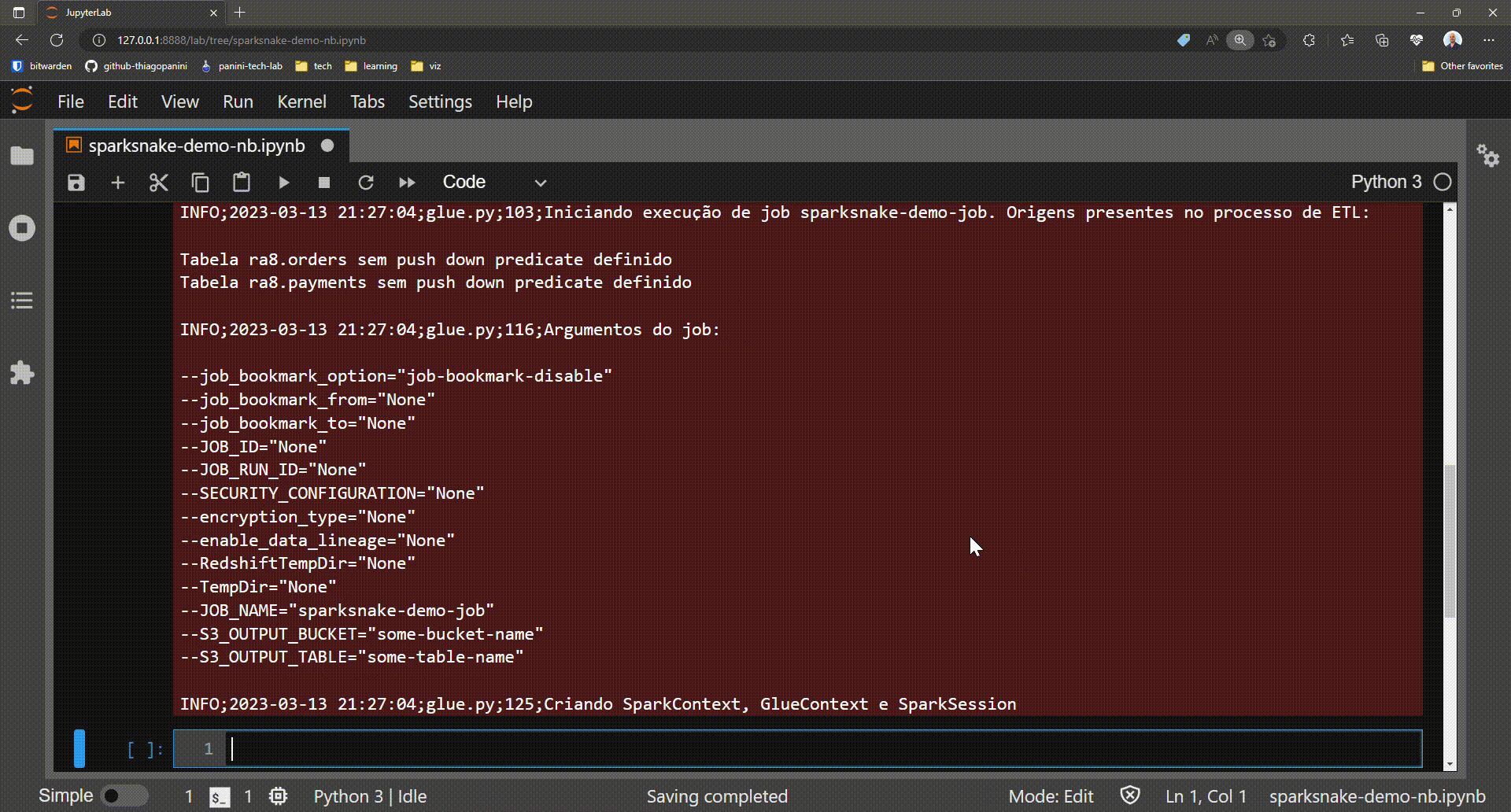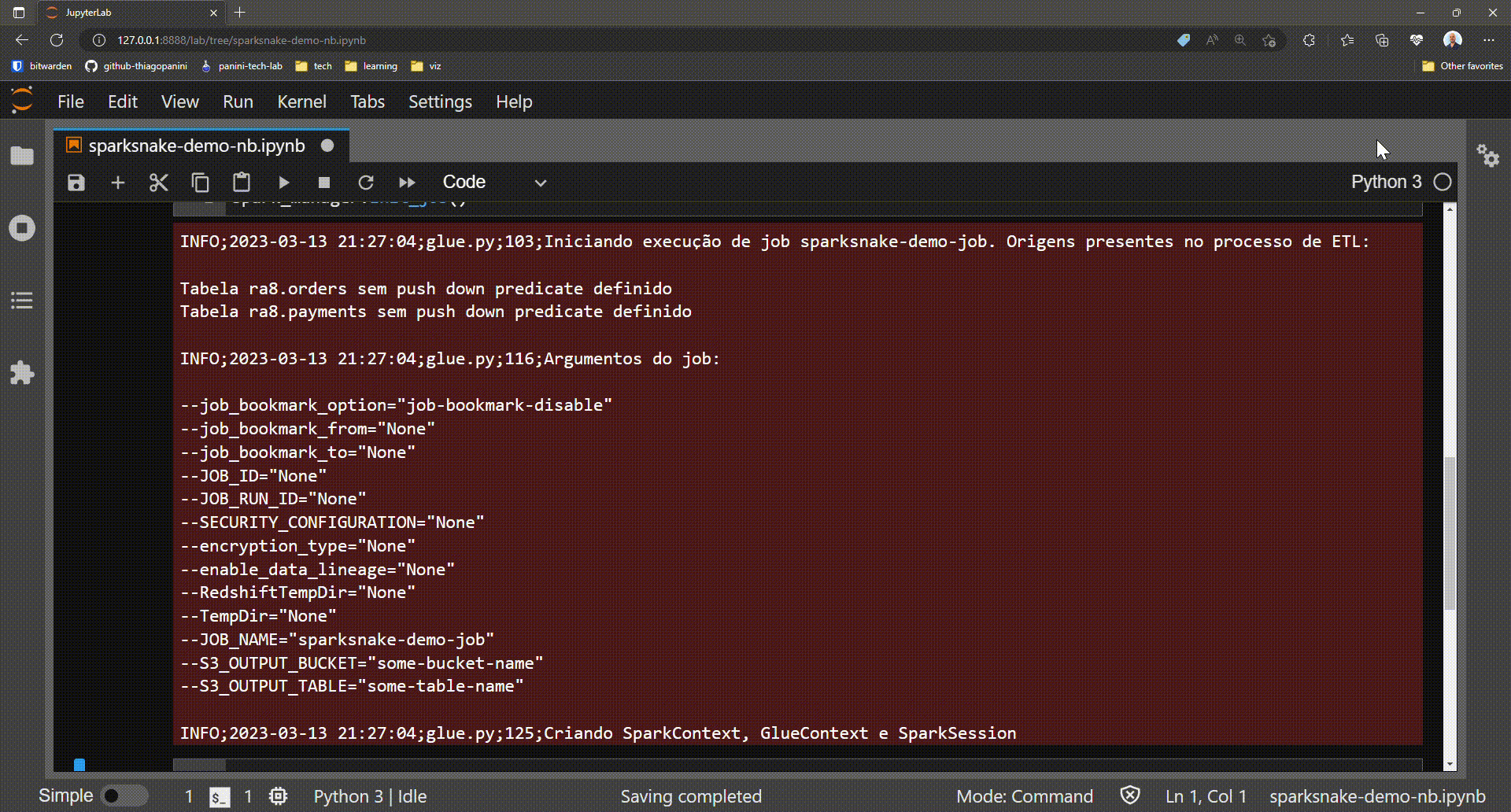
- Provides a detailed log message with useful information about the job
 Code:
Code:
# Initializing and getting all elements required by a Glue job
spark_manager.init_job()
 Learn more at GlueJobManager.init_job()
Learn more at GlueJobManager.init_job()
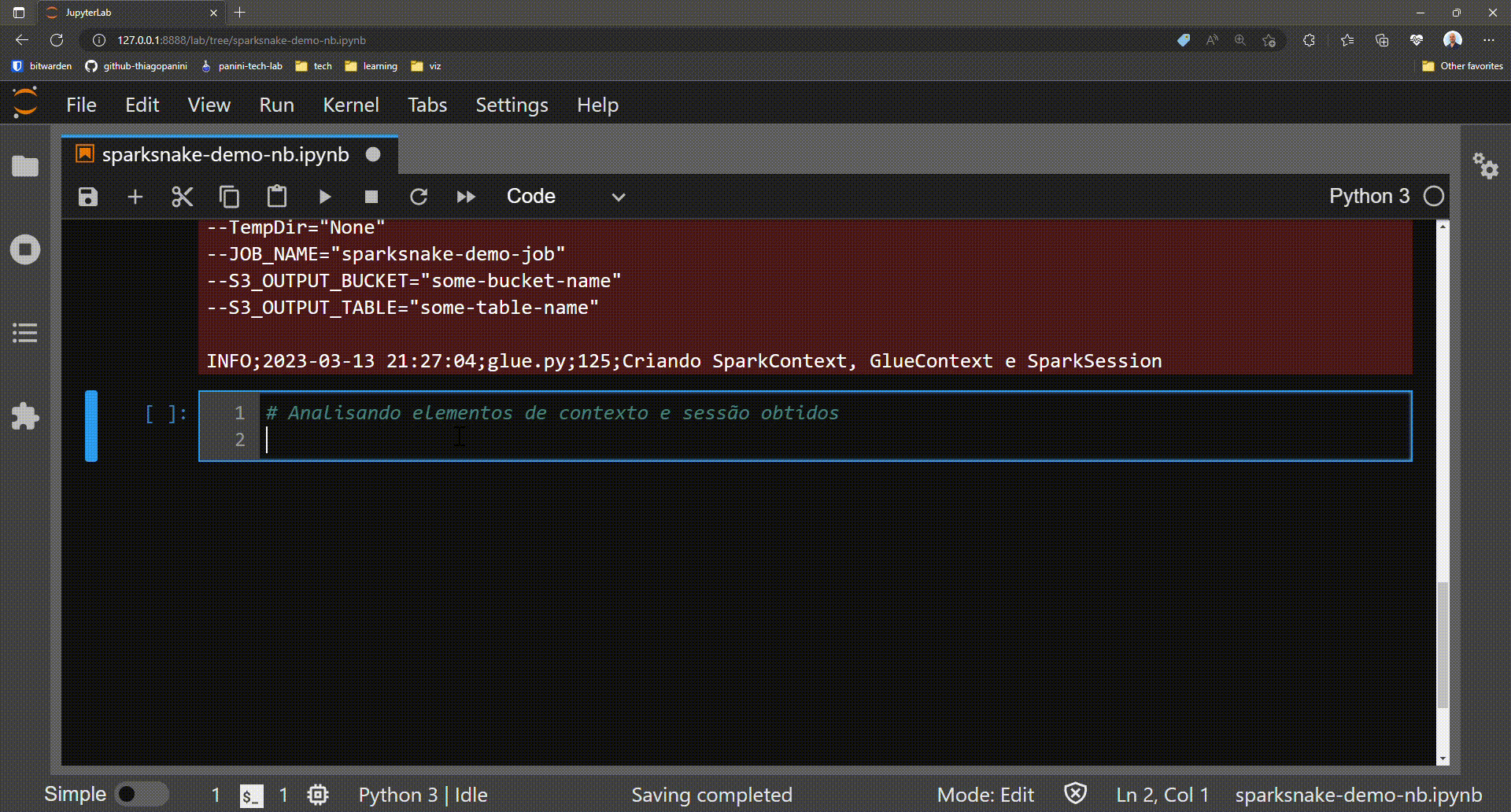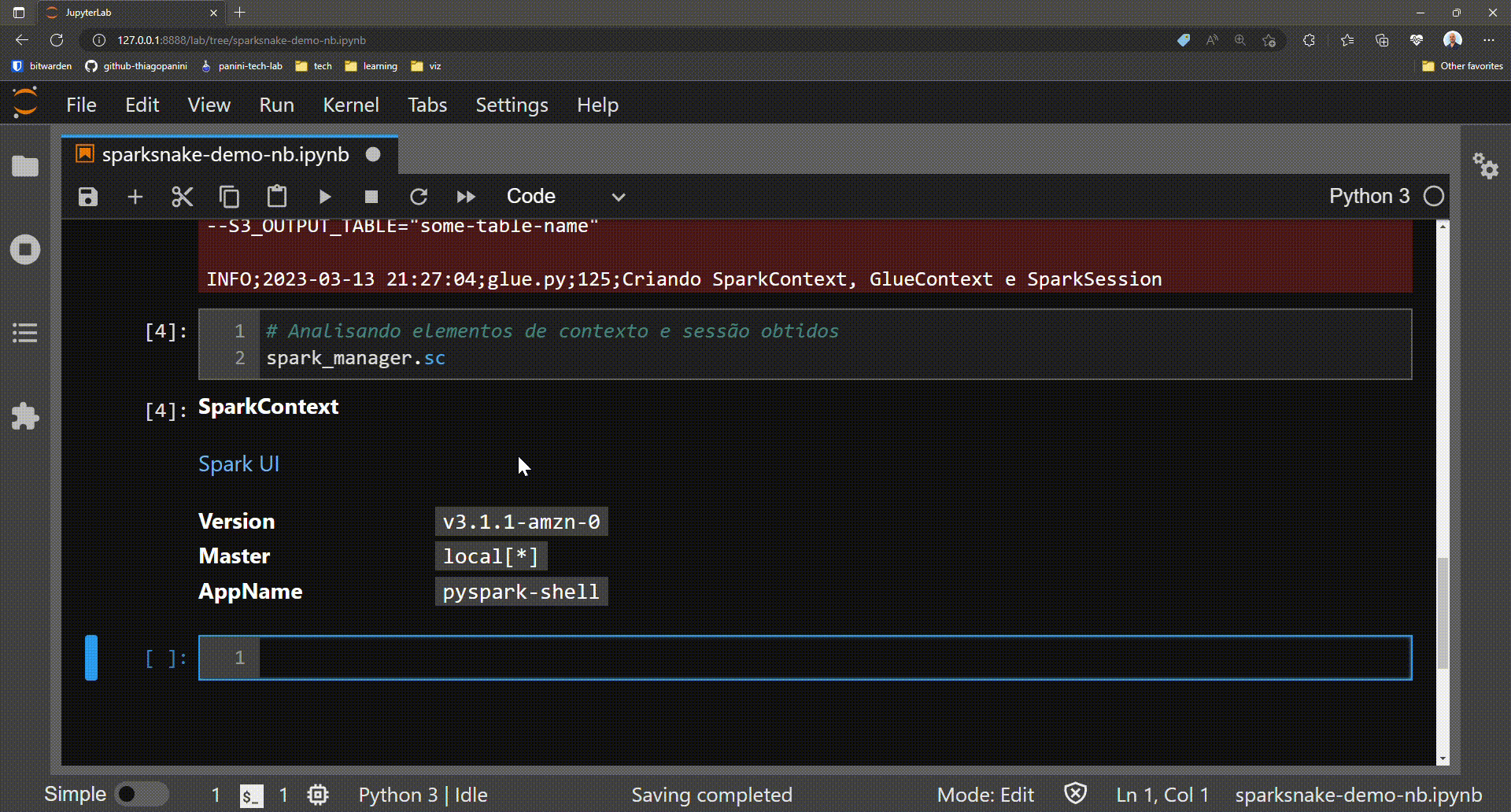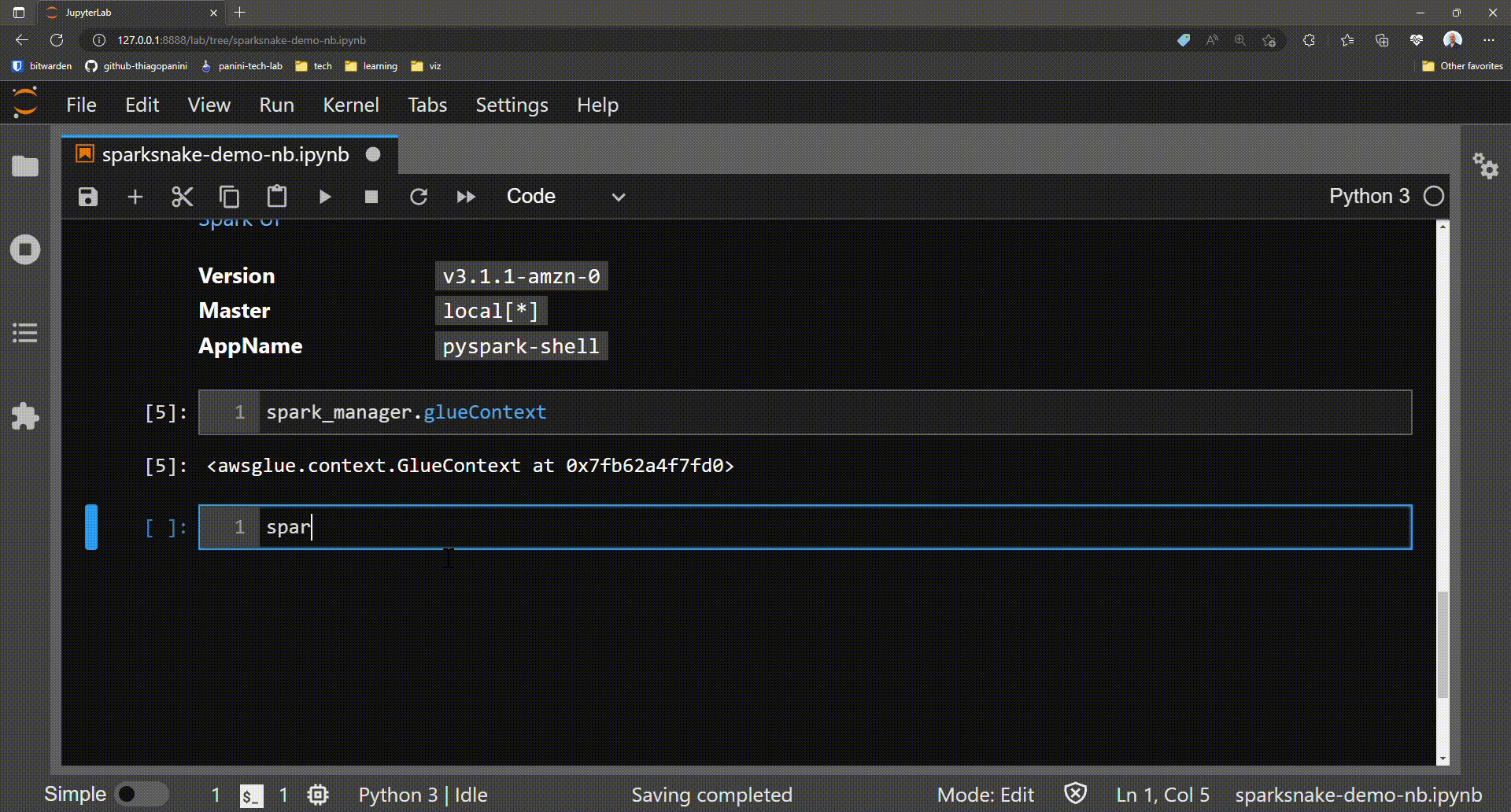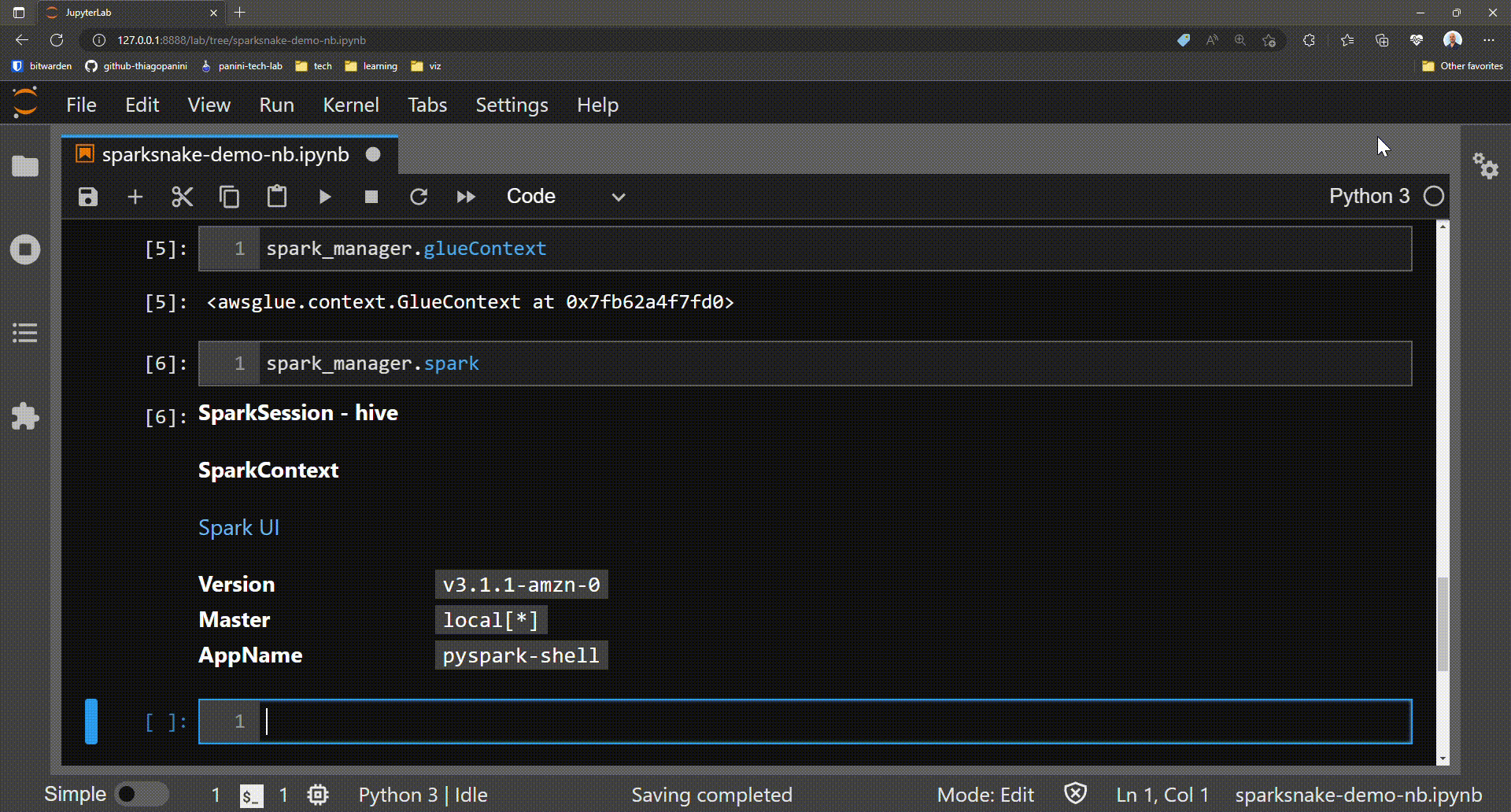
Optional: analyzing job required elements gotten by the method
As mentioned, the init_job() method is responsible for collecting and associating the Spark context, Glue context, and Spark session elements as attributes of the instantiated class. These three elements form the basis for performing Glue features throughout a job.
Reading Multiple Spark DataFrames¶
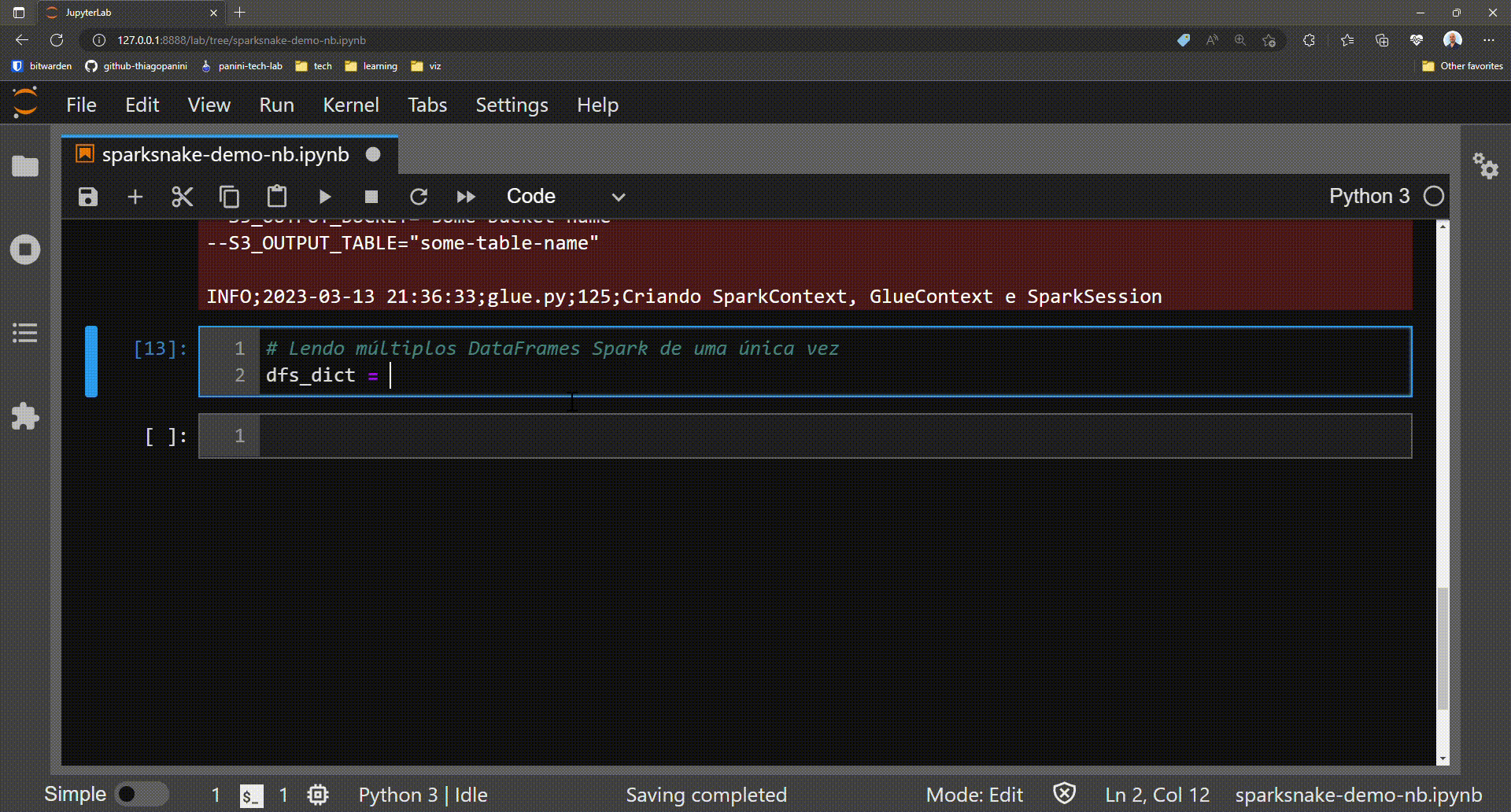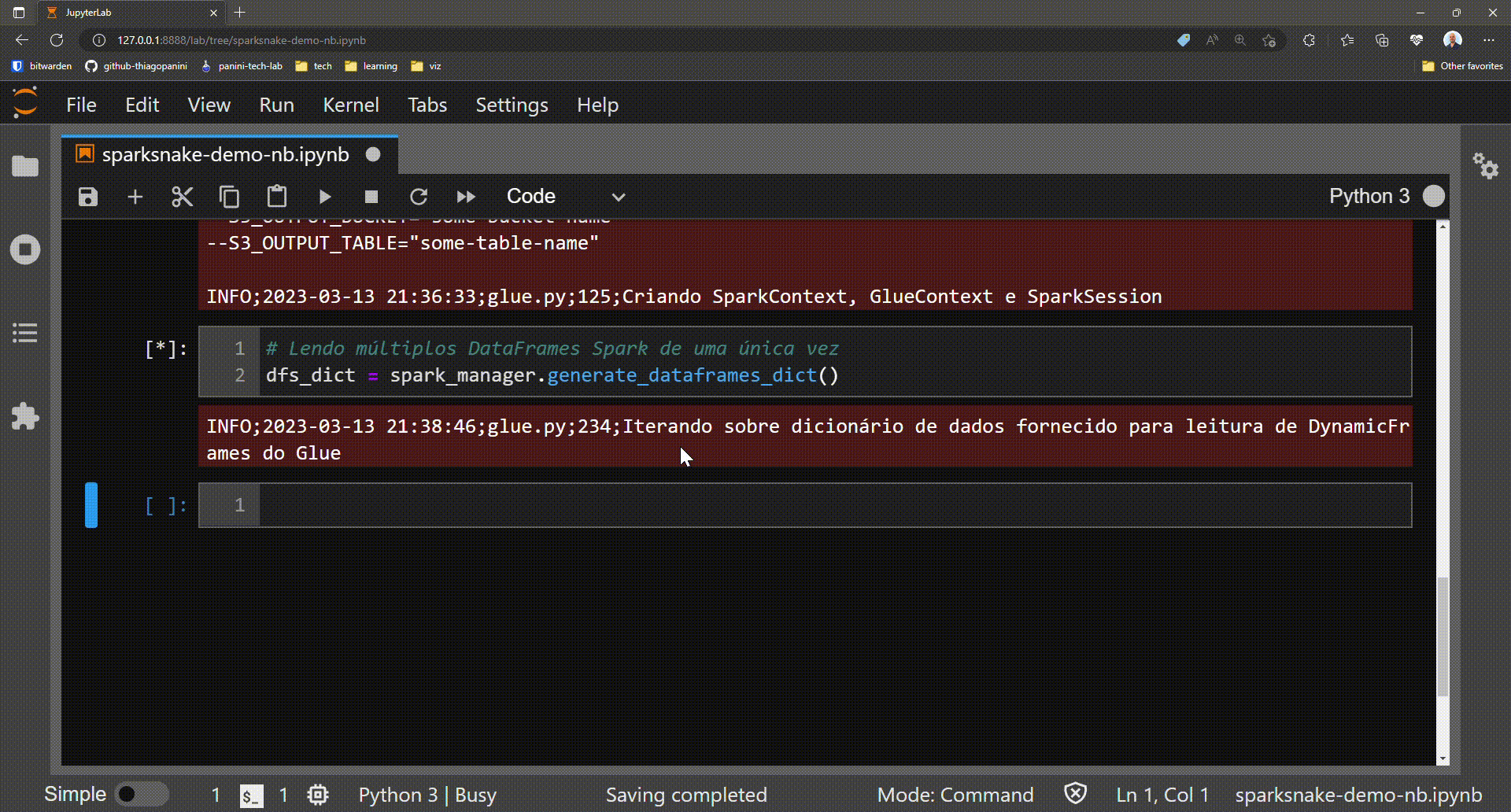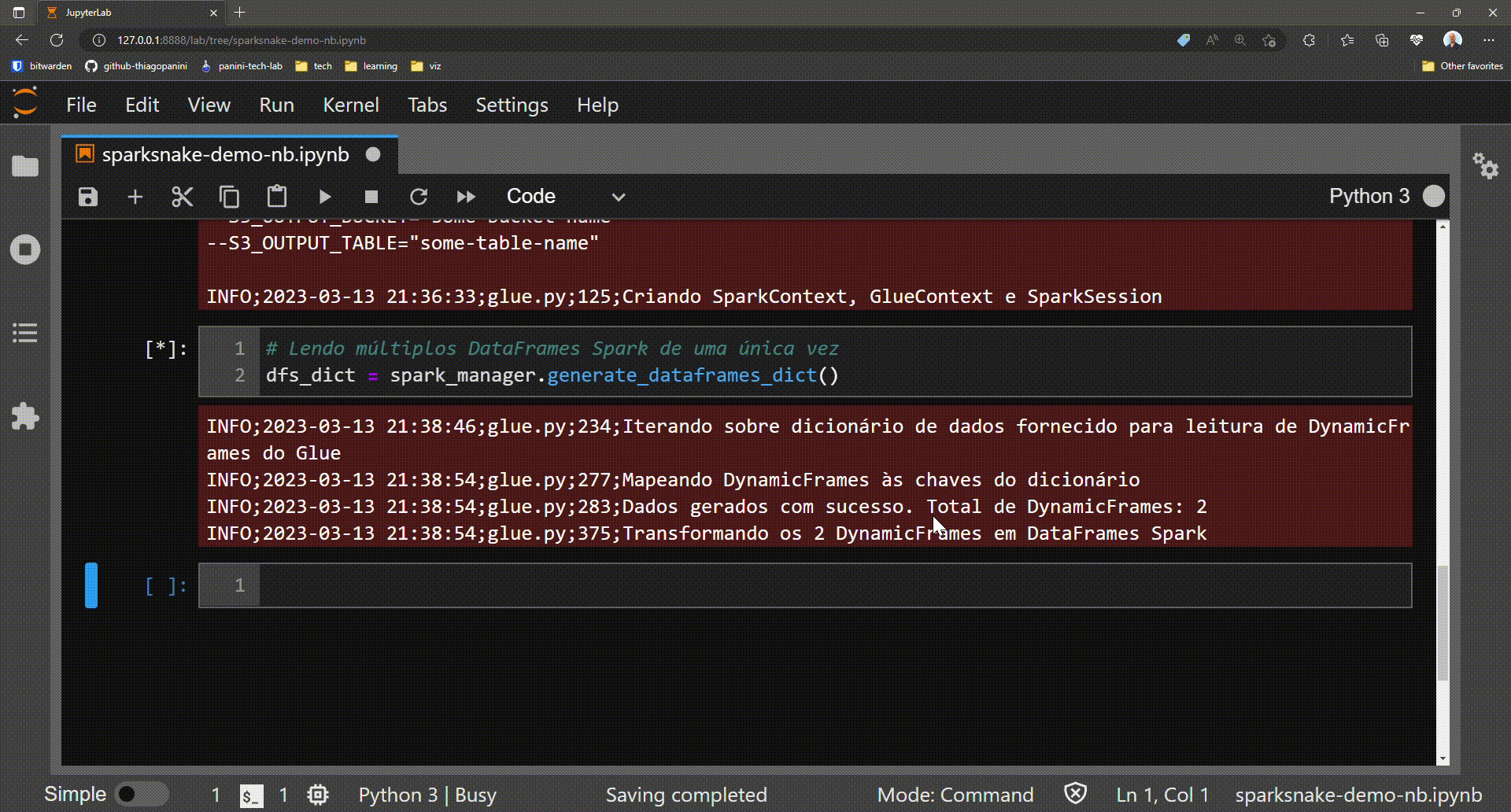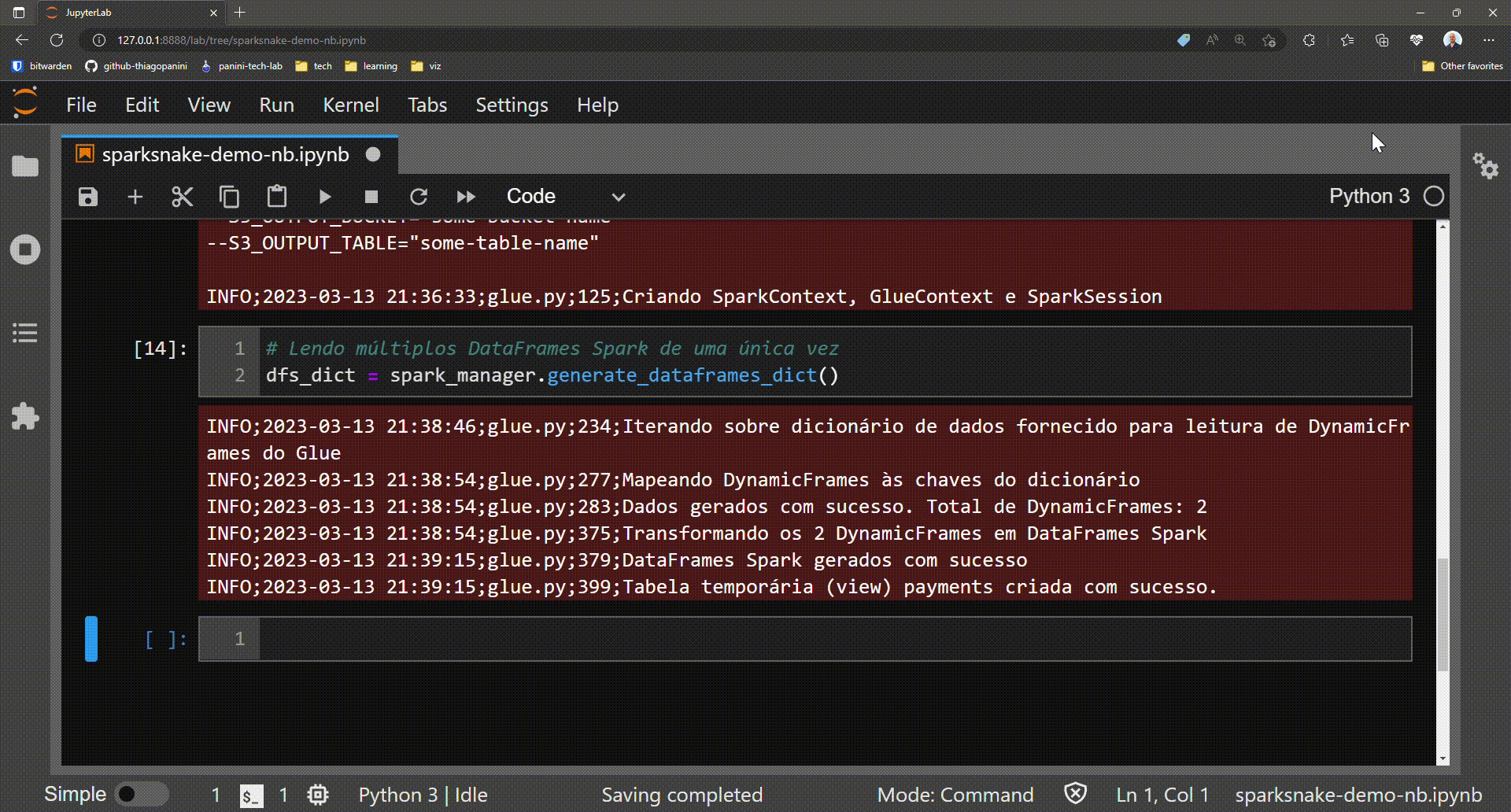
Following the demo journey, after the entire process of setting up and initializing and obtaining the job's elements, the time to read the source data has finally come. For that, the data_dict attributes will be used on the generate_dataframes_dict() method for providing a way to read multiple Spark DataFrames with a single line of code.
Getting a dictionary of Spark DataFrames objects
Demonstration:
Advantages and benefits:
- Obtaining multiple Spark DataFrames with a single line of code
- Better observability through detailed log messages
- Better code organization as the number of sources grows
- Possibility of automatic creation of temp views for mapped data sources
Code:
# Reading multiple Spark DataFrames at once
dfs_dict = spark_manager.generate_dataframes_dict()
Learn more at GlueJobManager.generate_dataframes_dict()
Optional: Analyzing the dictionary collected and unpacking DataFrames
After the method generate_dataframes_dict() is run, the user has a dictionary that maps variable keys to objects of DataFrame type. To get the DataFrames individually in the application, you must "unpack" the resulting dictionary as follows:
What More Can Be Done?¶
Now that we initialized a Glue Job and read all data sources as Spark DataFrames in the application, many possibilities are opened. At this point, the user can apply their own transformation methods, queries in SparkSQL or any other operation that makes sense within their own business rules.
The sparksnake, as a library, does not claim to encapsulate all existing business rules within a Glue job. This would be virtually impossible. However, one of the advantages of sparksnake is to enable some common features that can be extremely useful within the journey of code development and application of business rules. And that's what you will see in the following sections.
Extracting Date Attributes¶
One of the features available in sparksnake allows users to enrich a Spark DataFrame with a series of date attributes extracted from a DataFrame column that represents a date information. In other words, this is an easy and efficient way to get new attributes in a DataFrame like year, month, day, quarter, day of the week and much more with the power of the method date_transform().
To see how this work in practice, let's create a simplified version of the df_orders DataFrame selecting only a few attributes for demo purposes.
Prepartion: creating a simplified version of df_orders DataFrame
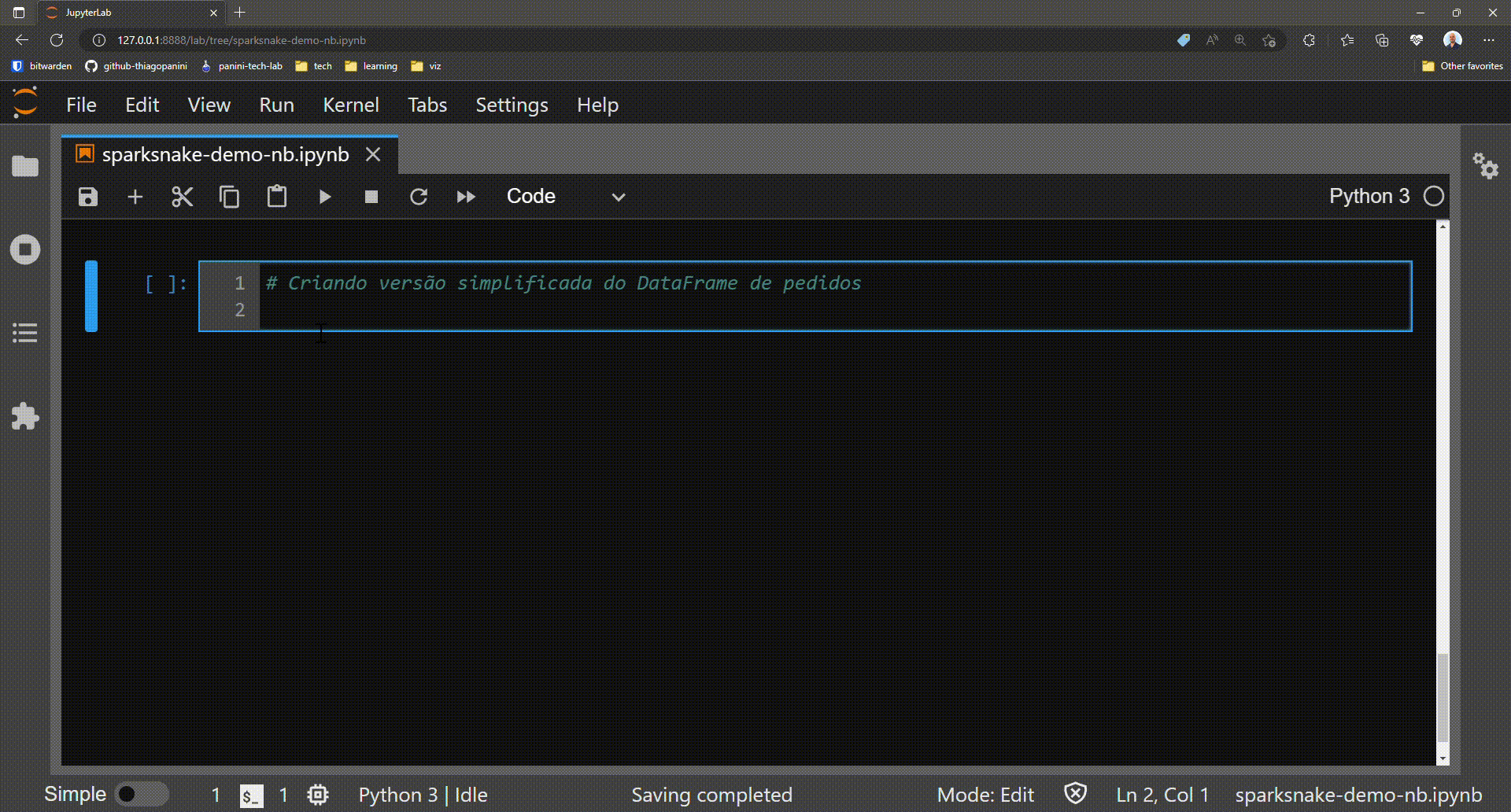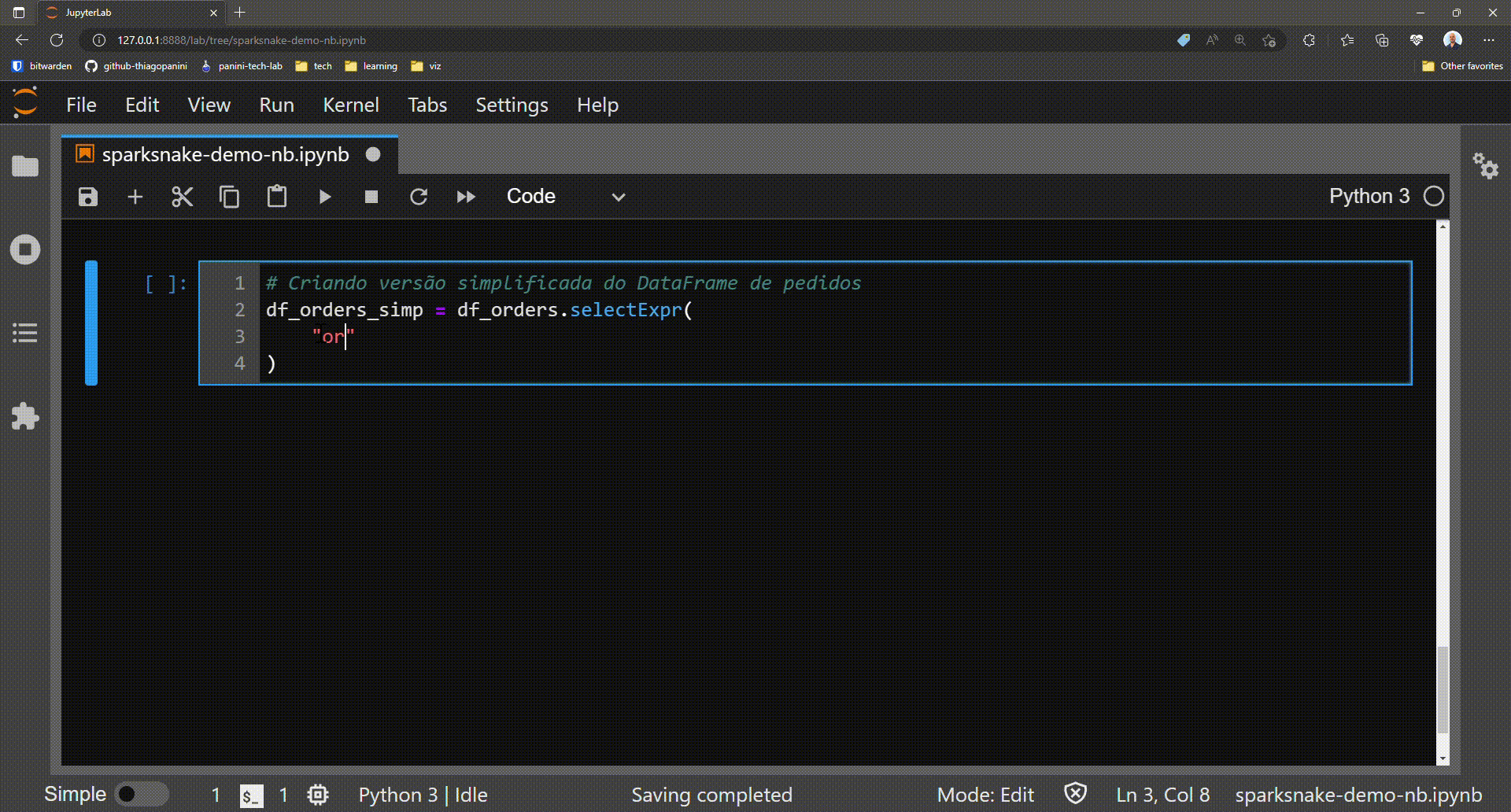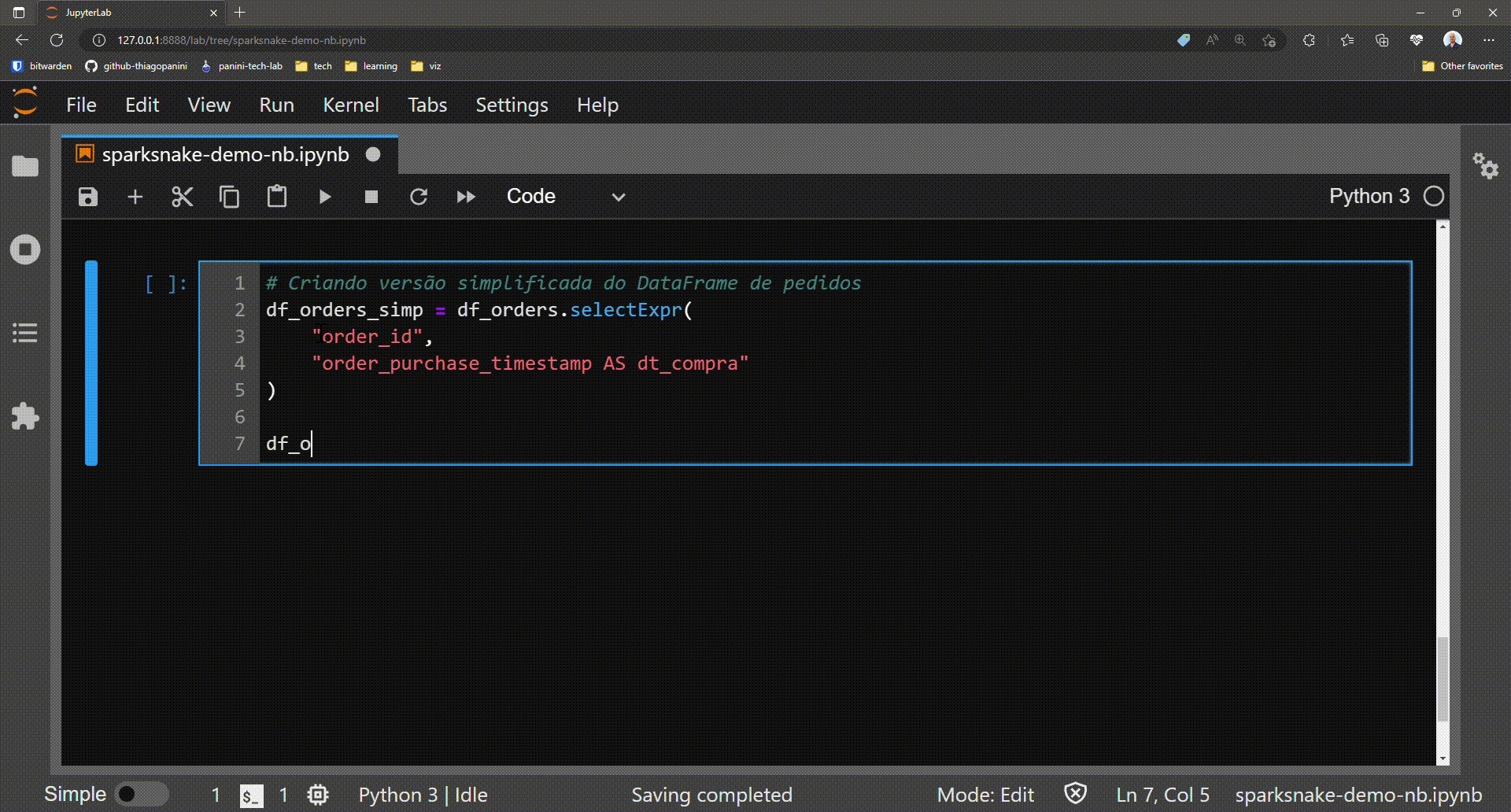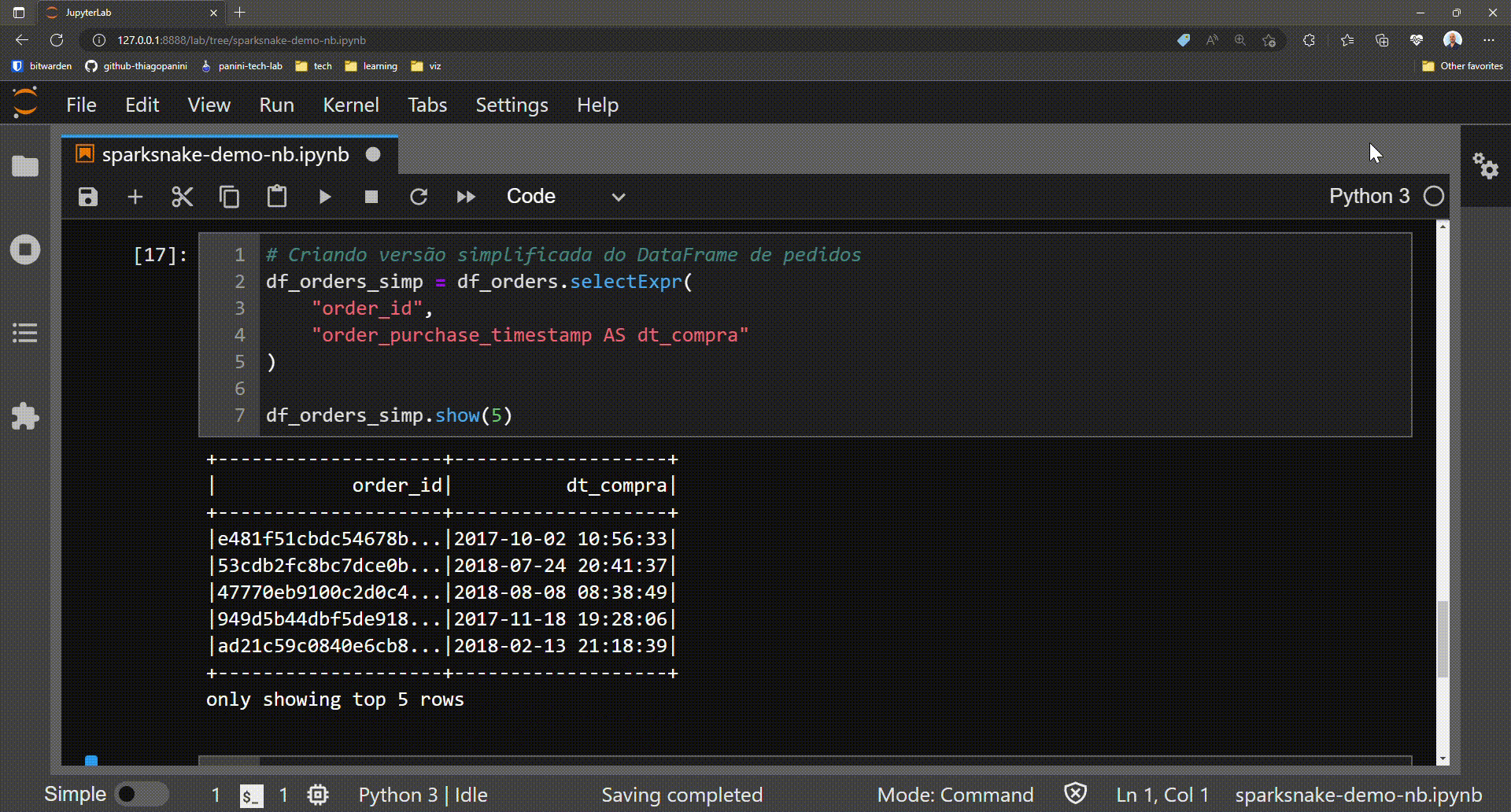
Now the target DataFrame for the demo has only two columns: order_id and dt_compra. The final goal is to obtain a bunch of date attributes from the dt_compra column.
Getting date attributes from a date column in a DataFrame
Demonstration:
![]()
Advantages and benefits:
- Enrich the data analysis process with date attributes extracted in a easy way
- Abstraction of complex queries and functions calls for extract date information
- Option to automatically convert strings in date or timestamp columns
Code
# Creating a simplified version of orders DataFrame
df_orders_simp = df_orders.selectExpr(
"order_id",
"order_purchase_timestamp AS dt_compra"
)
# Extracting date attributes from a date DataFrame column
df_orders_date = spark_manager.date_transform(
df=df_orders_simp,
date_col="dt_compra",
convert_string_to_date=False,
year=True,
month=True,
dayofmonth=True
)
# Showing the result
df_orders_date.show(5)
Learn more at SparkETLManager.date_transform()
Optional: extracting all possible date attributes
To bring a complte view of this feature, the video below uses all the date attributes flag available in the method to enrich a DataFrame with all possibilities.
Obs: the video above was recorder when this method was called extract_date_attributes() and not date_transform() (current version).
Extracting Statistical Attributes¶
Another powerful feature inside sparksnake allows users to extract a series of statistical attributes based on a numeric column and a set of columns to be grouped in the aggregation process. With the method agg_data() the users can enrich their data analysis and get specialized DataFrames to answear all possible business questions.
To see this in practice, let's now use the df_payments DataFrame with payments data of online orders.
Preparation: showing a sample of the target df_payments DataFrame
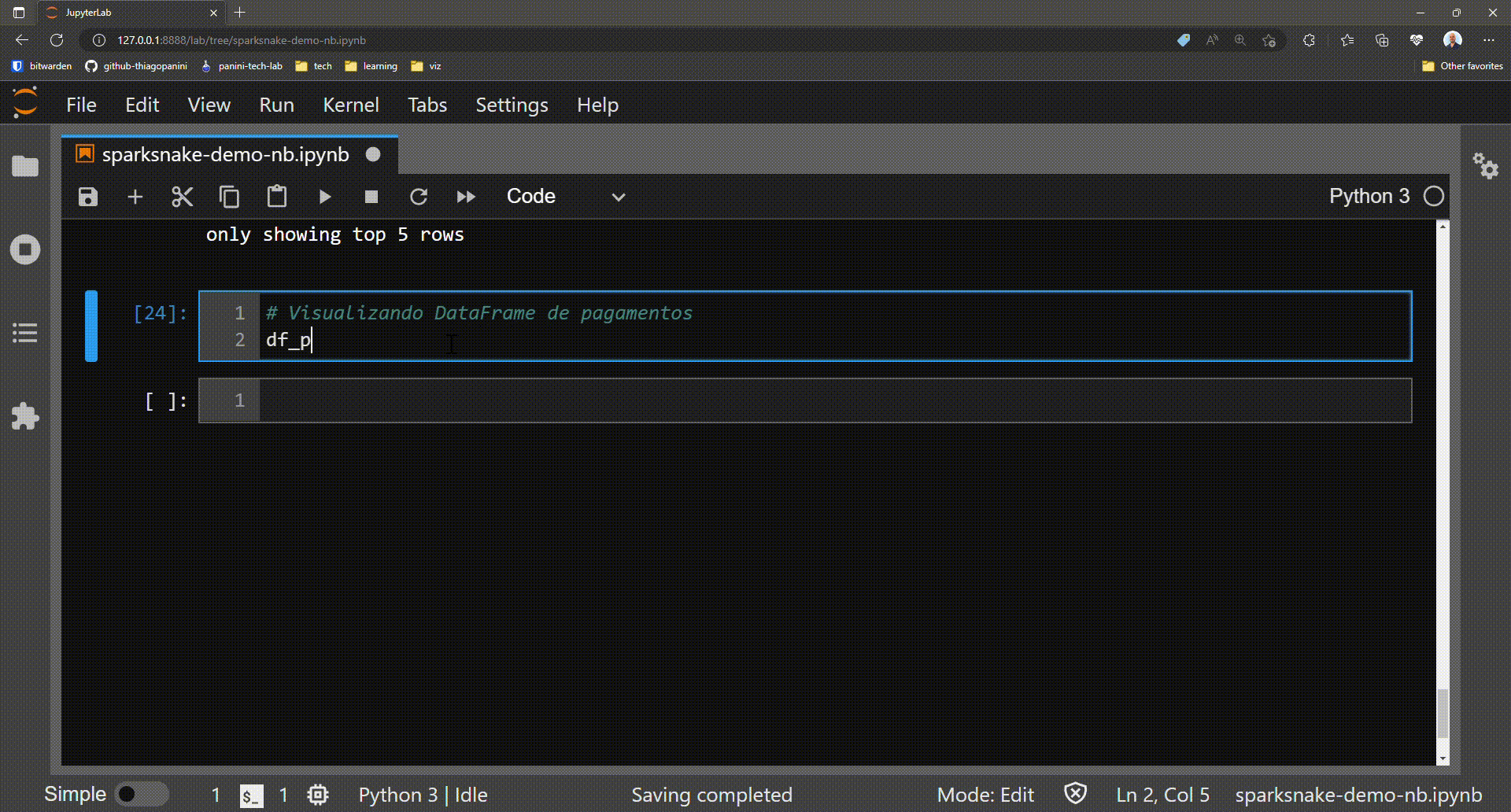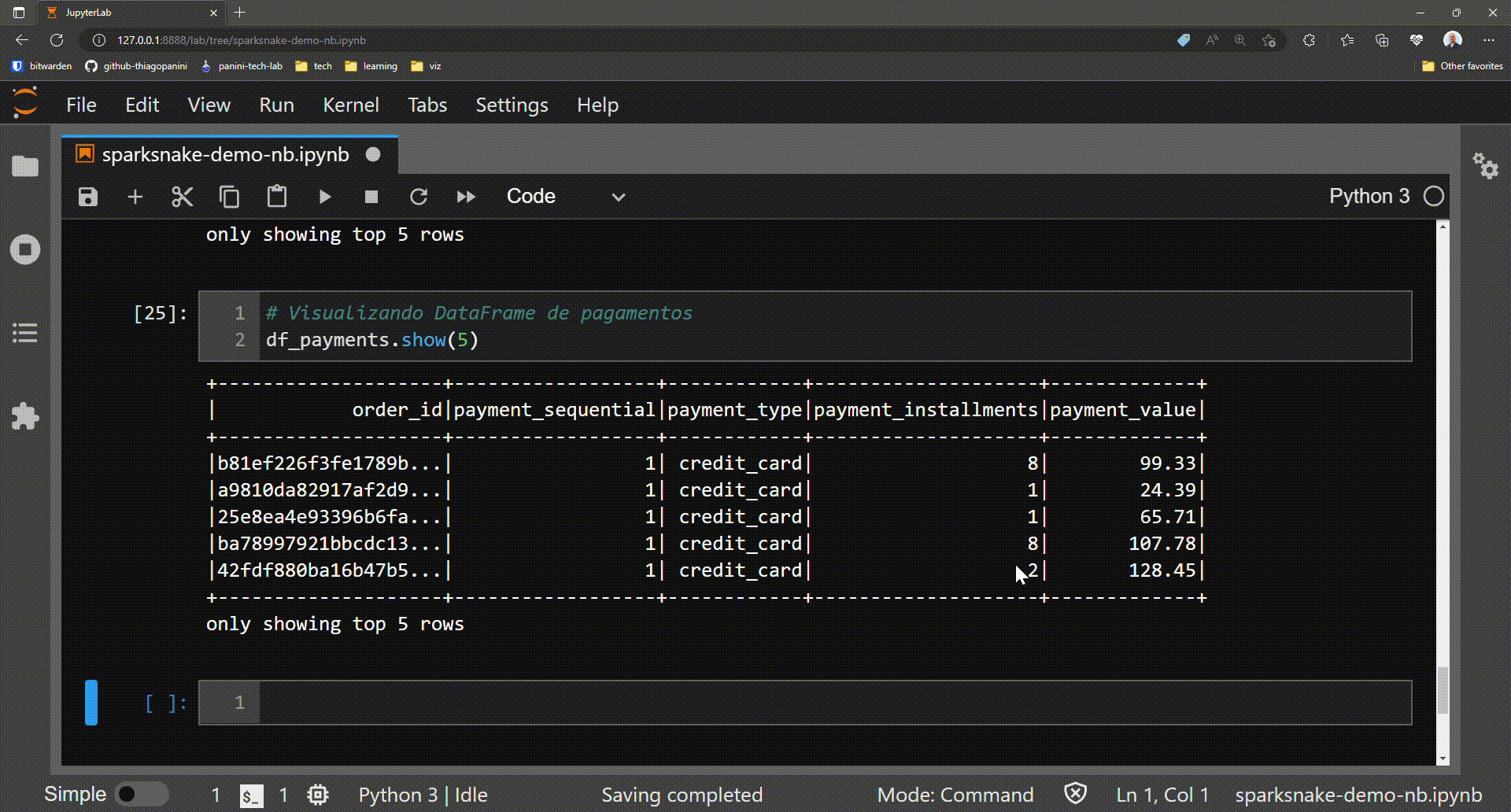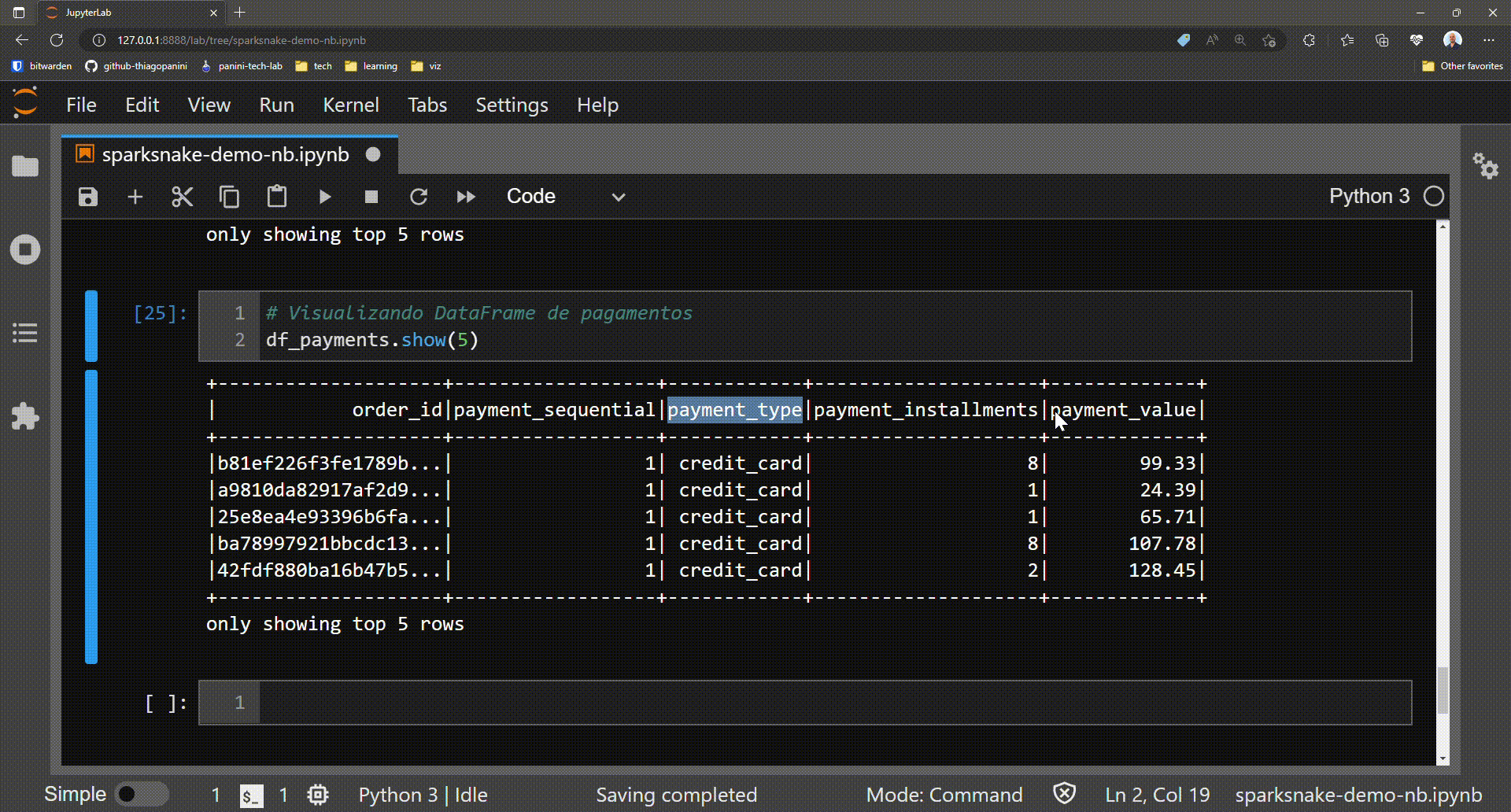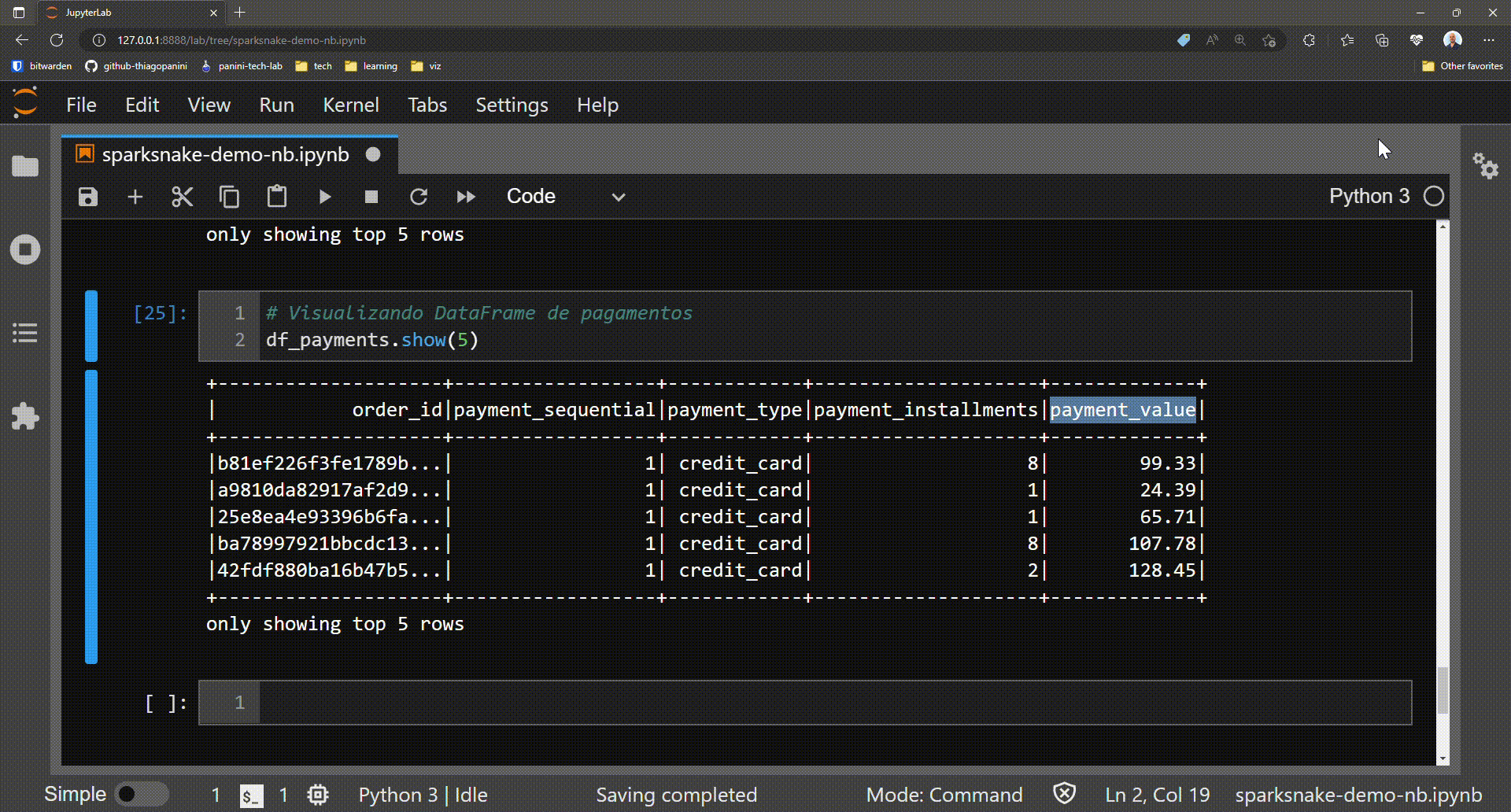
The columns of the DataFrame show an interesting possibility of applying analytics on payment values for each payment type. Maybe it would be very important to see the sum, mean, min and max for credit card payments compared to other categories. Let's do that with a single method call!
Getting statistical attributes from a DataFrame
Demonstration:
Advantages and benefits:
- Extract multiple statistical attributes with a single method call
- Enhancement of analytics
- Reduced complexity about aggregation process in pyspark
- Option to group by multiple columns
Code
df_payments_stats = spark_manager.agg_data(
df=df_payments,
numeric_col="payment_value",
group_by="payment_type",
round_result=True,
n_round=2,
count=True,
sum=True,
mean=True,
max=True,
min=True,
)
# Showing results
df_payments_stats.show(5)
Learn more at SparkETLManager.agg_data()
Dropping Partitions in S3¶
When developing and running Glue jobs on AWS, a situation that is always present is partitioning tables in S3. In some cases, it is essential to avoid creating duplicate data on existing partitions. In this way, the method drop_partition() enables a way to physically delete partitions in S3 before new data writing processes.
To demonstrate this feature, a new tab of an AWS account will be open to prove the existence of the partition before the method is run and its deletion after it is run.
Eliminating physical partitions in S3
Demonstration:
Advantages and benefits:
- Applying of the purge method in a S3 partition to drop the prefix and all the data inside it
- Possibility of chaining the drop method and a write method
- Prevent duplicated data after running the same job twice
Code
# Defining partition URI
partition_uri = "s3://some-bucket-name/some-table-name/some-partition-prefix/"
# Puring partition in S3
spark_manager.drop_partition(partition_uri)
Learn more at GlueJobManager.drop_partition()
Adding Partitions to DataFrames¶
In ETL processes, it is common to have operations that generate datasets partitioned by existing attributes and/or date attributes that refer to the time instant of job execution. For cases where you need to add one or more partition columns to an existing DataFrame Spark, the method add_partition_column() encapsulates the execution of the method withColumn() to add a column to an existing DataFrame.
Adding a partition column to a Spark DataFrame
Demonstration:
Advantages and benefits:
- Abstraction of the already available add column method in a DataFrame
- Greater clarity of operations in an ETL flow by expliciting putting a "partition addition" call as a method
- Possibility to combine the
drop_partition()and theadd_partition_column()in a data flow
Code
from datetime import datetime
# Adding a date partition in a DataFrame base on the date of job execution
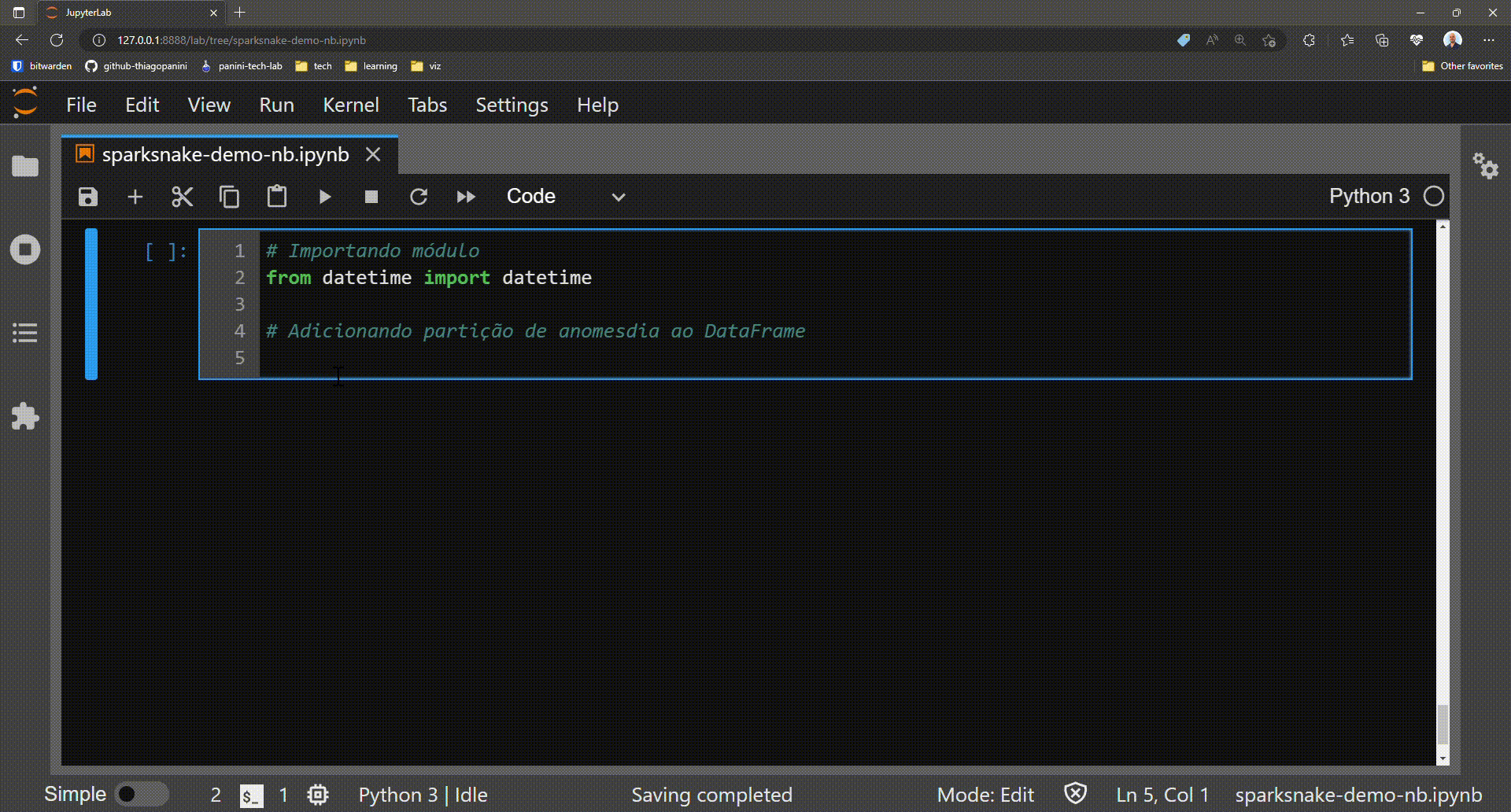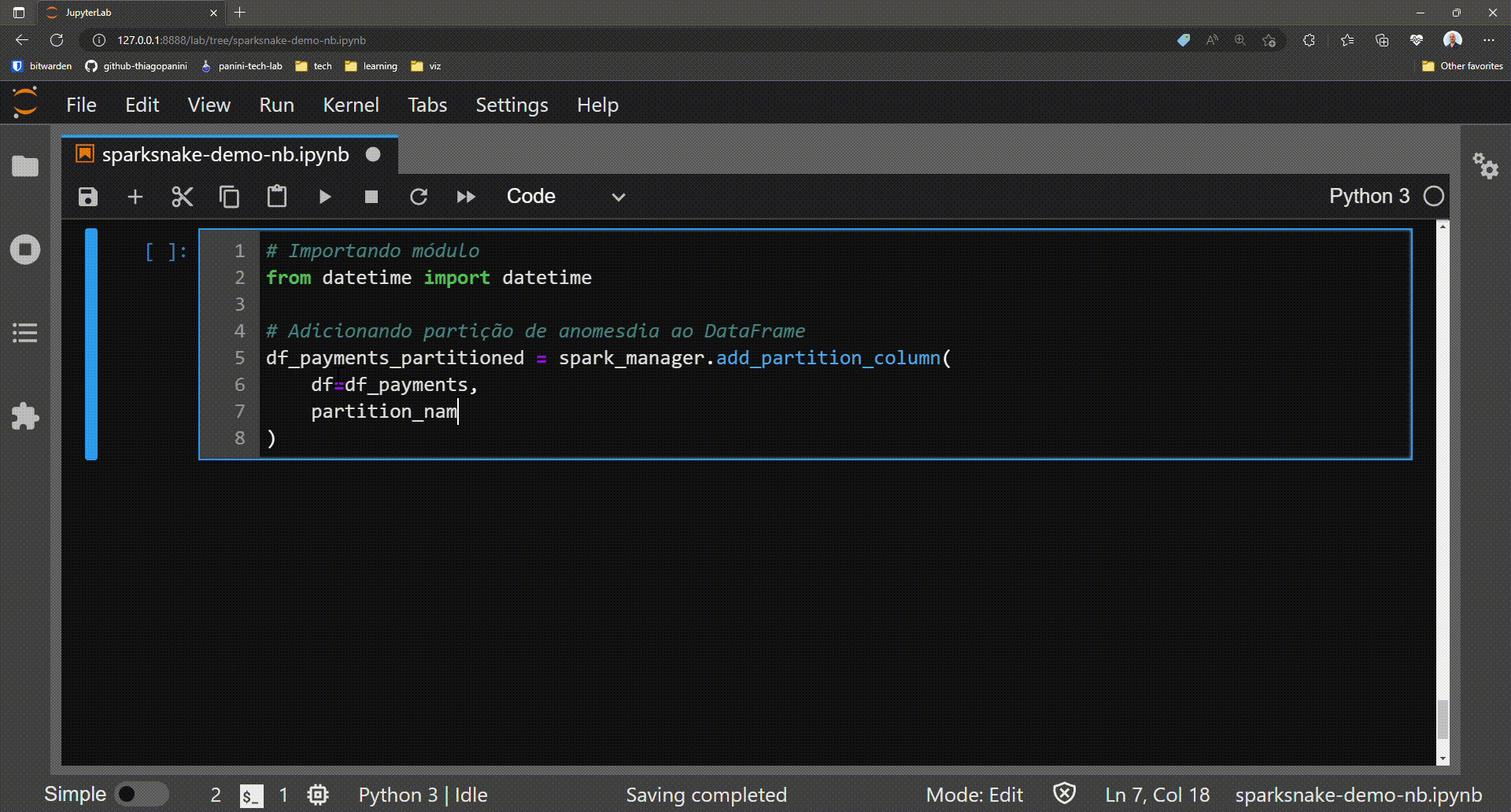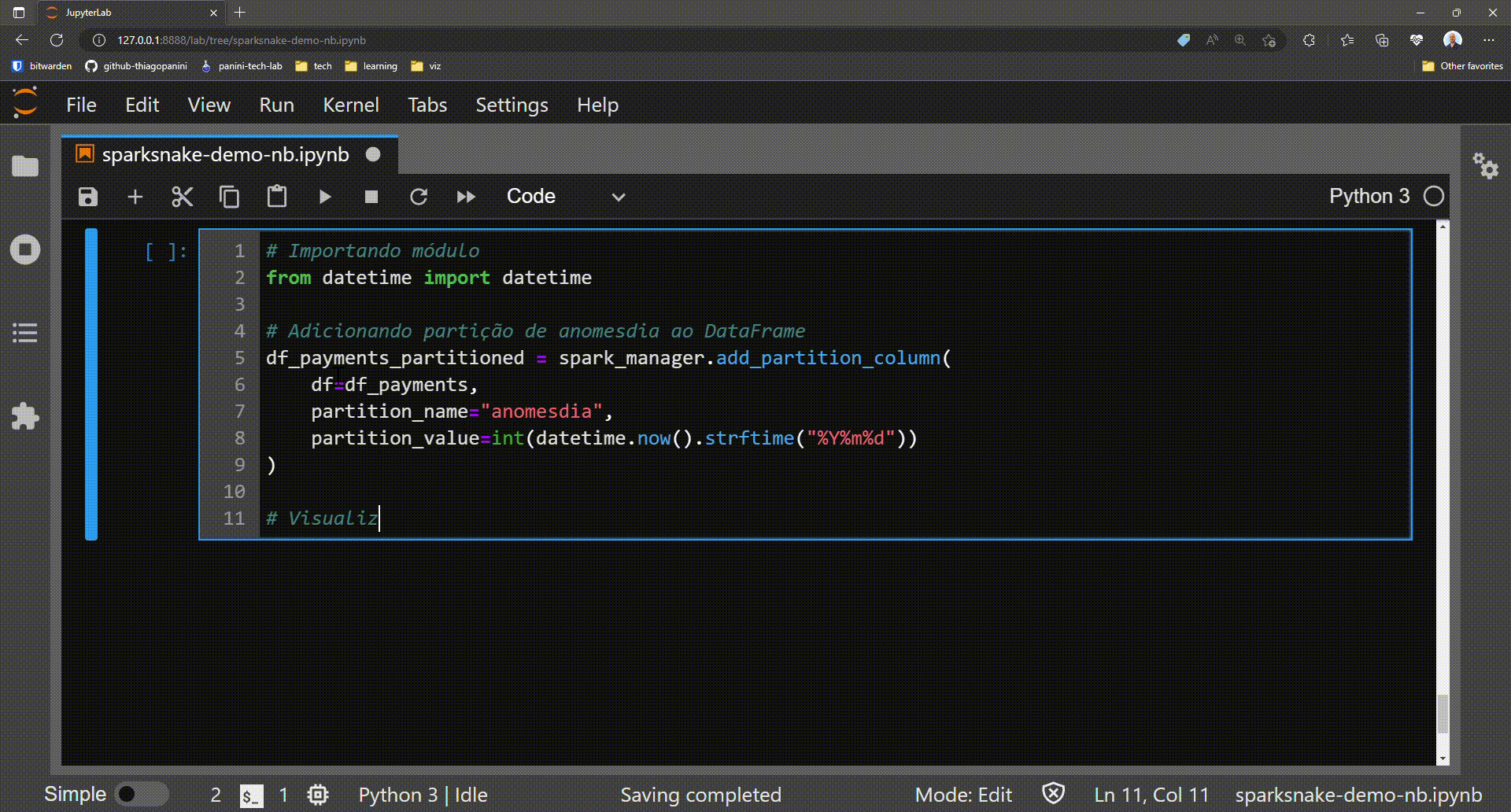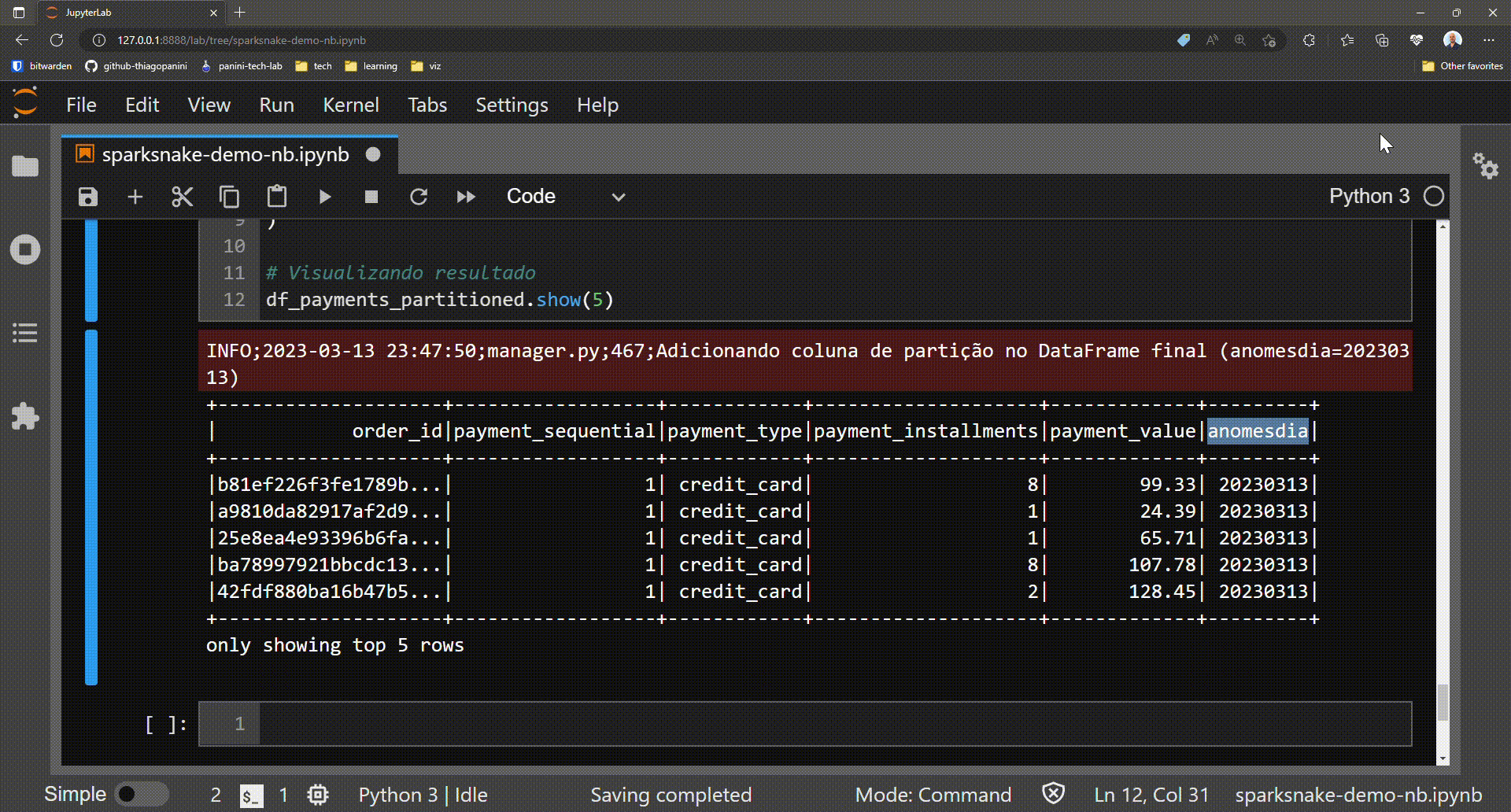
df_payments_partitioned = spark_manager.add_partition(
df=df_payments,
partition_name="anomesdia",
partition_value=int(datetime.now().strftime("%Y%m%d"))
)
# Showing results
df_payments_partitioned.show(5)
Learn more at SparkETLManager.add_partition_column()
Repartitioning a DataFrame¶
In some workflows, thinking about ways to optimize the storage of distributed pools is essential to ensure efficiency and promote best consumption practices for process-generated data products. Repartition a Spark DataFrame can contribute to achieve this goal and in the sparksnake library the method repartition_dataframe() was created to assist the user in this process. Simply provide a target number of partitions and the functionality itself will manage which Spark method is best suited for the case (coalesce() or repartition()).
Modifying the number of physical partitions in a DataFrame
Demonstration:
Advantages and benefits:
- Optimized storing data proccess in a distributed storage system (e.g. S3)
- Contributes to the reduction of small files from a stored table
- Contributes to an increased query performance executed on the generated table
- Automatic selection between methods
coalesce()andrepartition()based on the current number collected from DataFrame partition
Code:
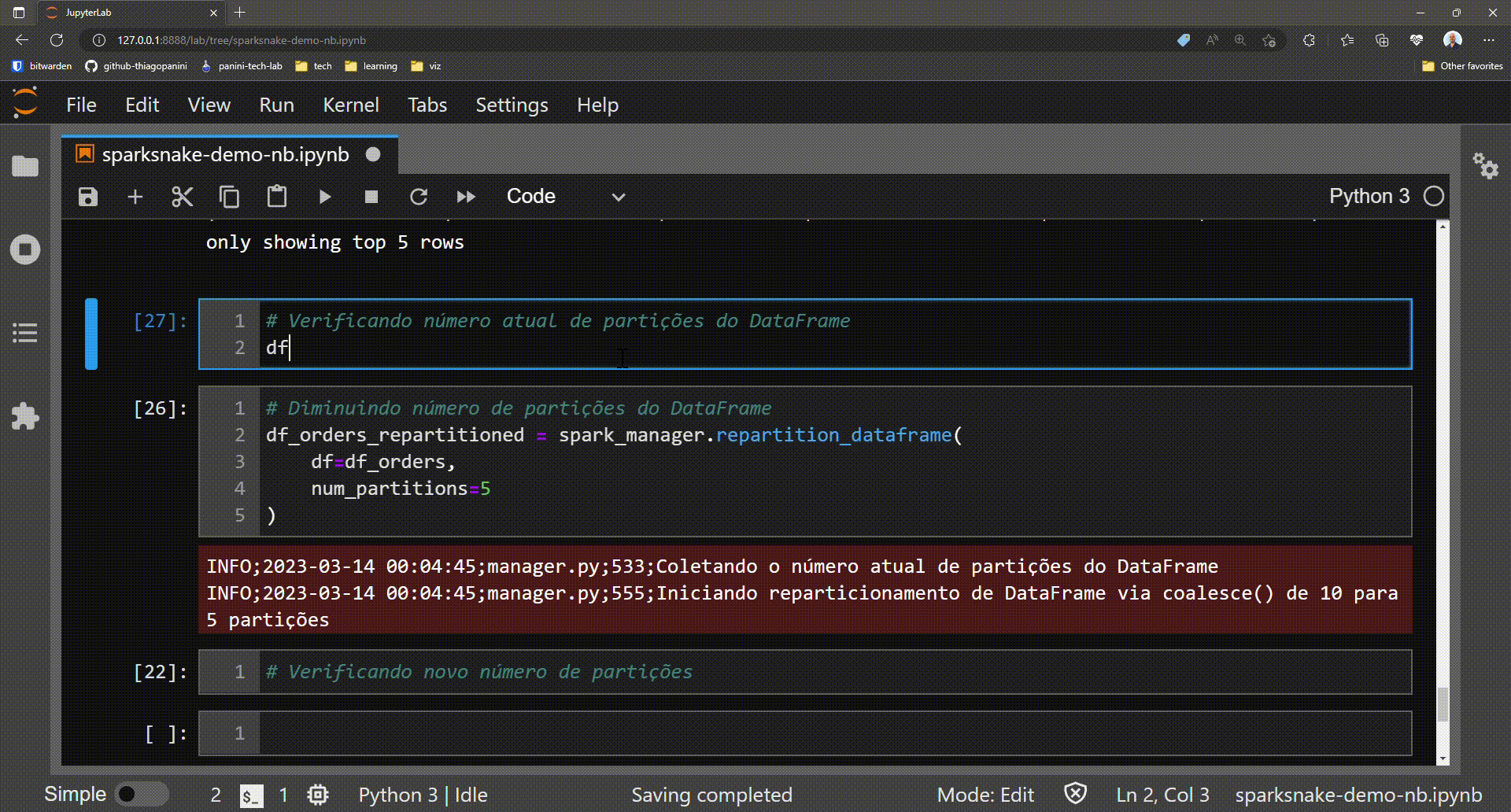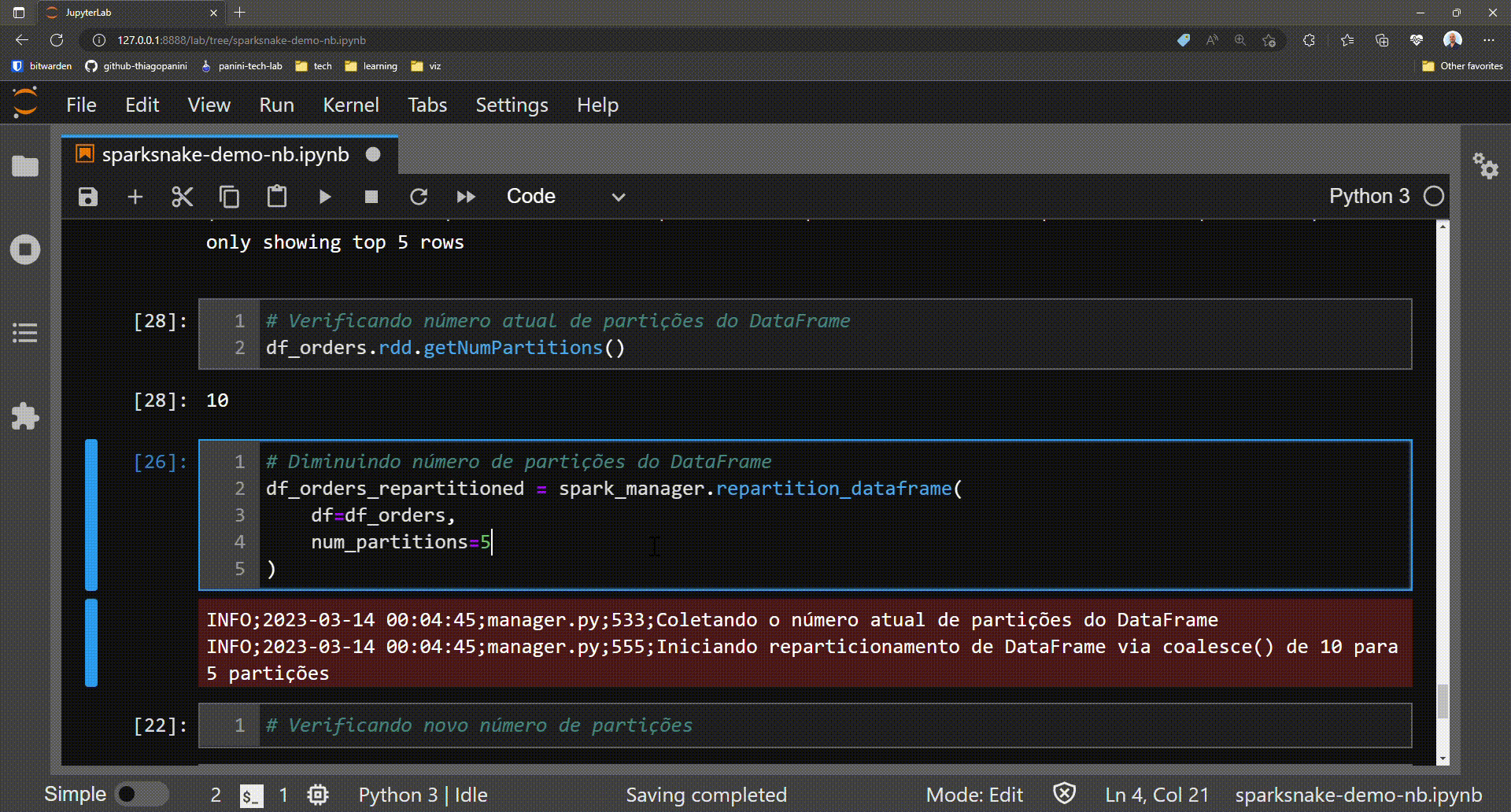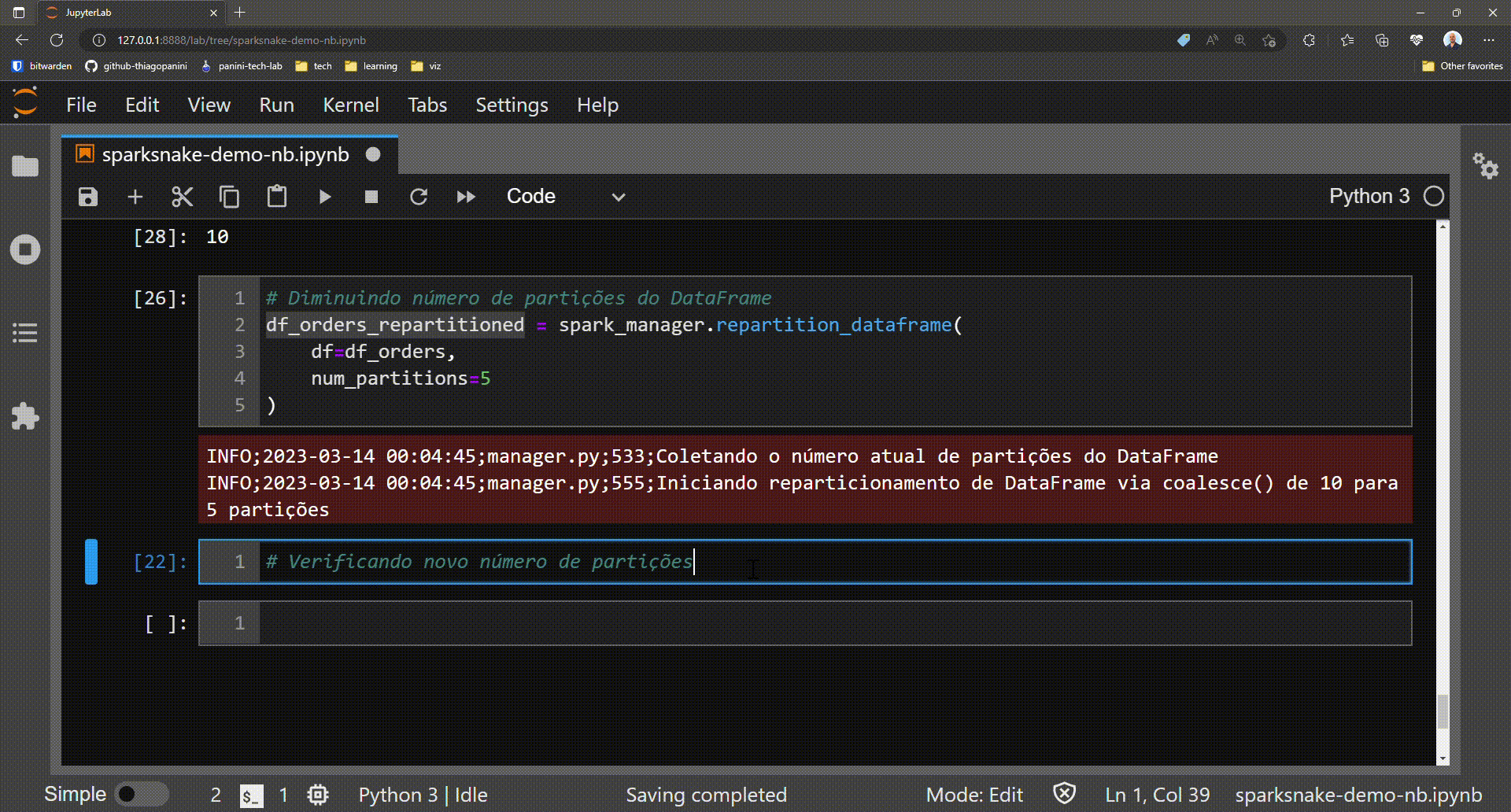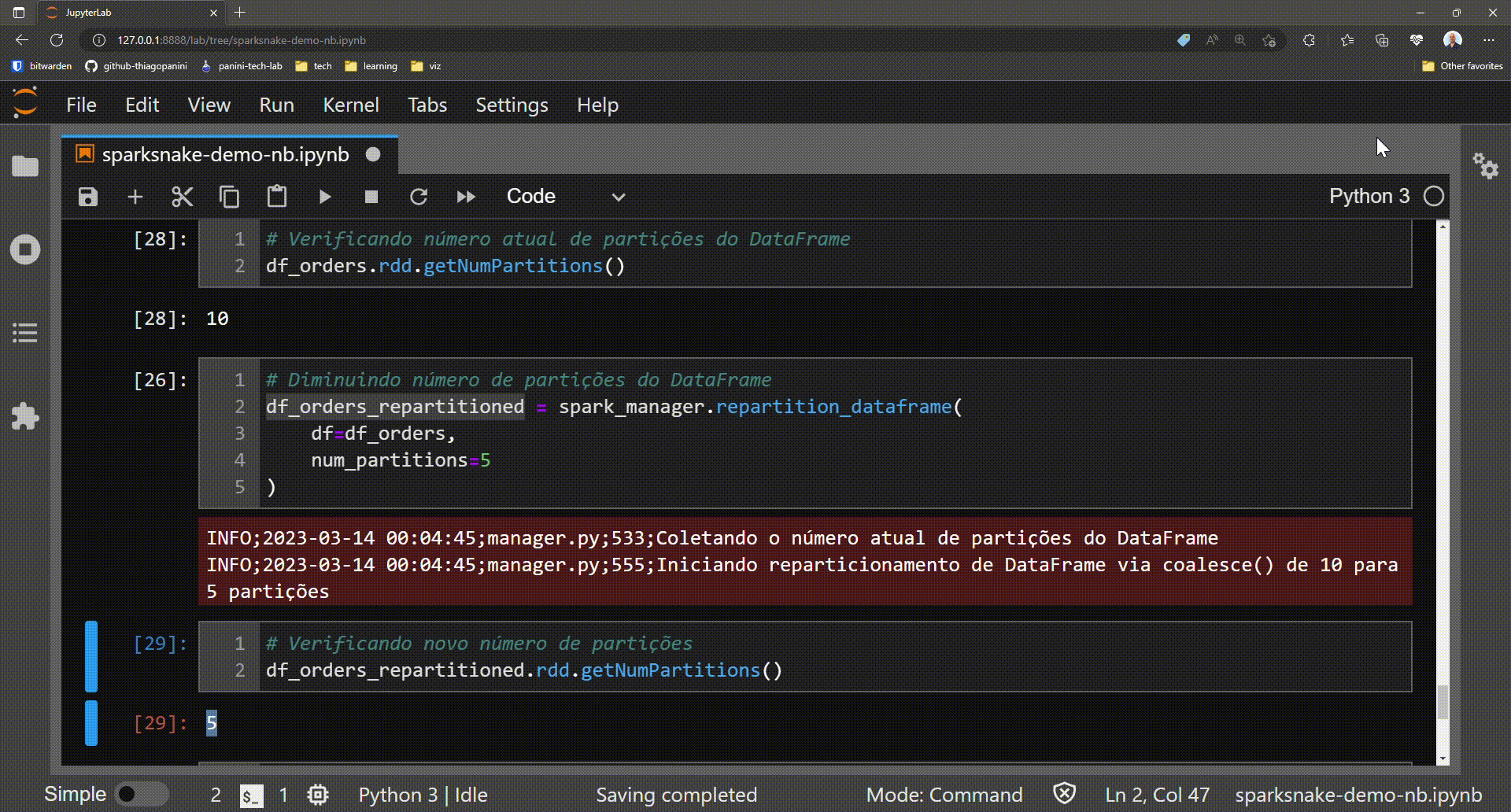
# Getting the actual number of partitions in a DataFrame
df_orders.rdd.getNumPartitions()
# Reducing the number of partitions
df_orders_partitioned = spark_manager.repartition_dataframe(
df=df_orders,
num_partitions=5
)
# Getting the new number of partitions after repartition
df_orders_partitioned.rdd.getNumPartitions()
Learn more at SparkETLManager.repartition_dataframe()
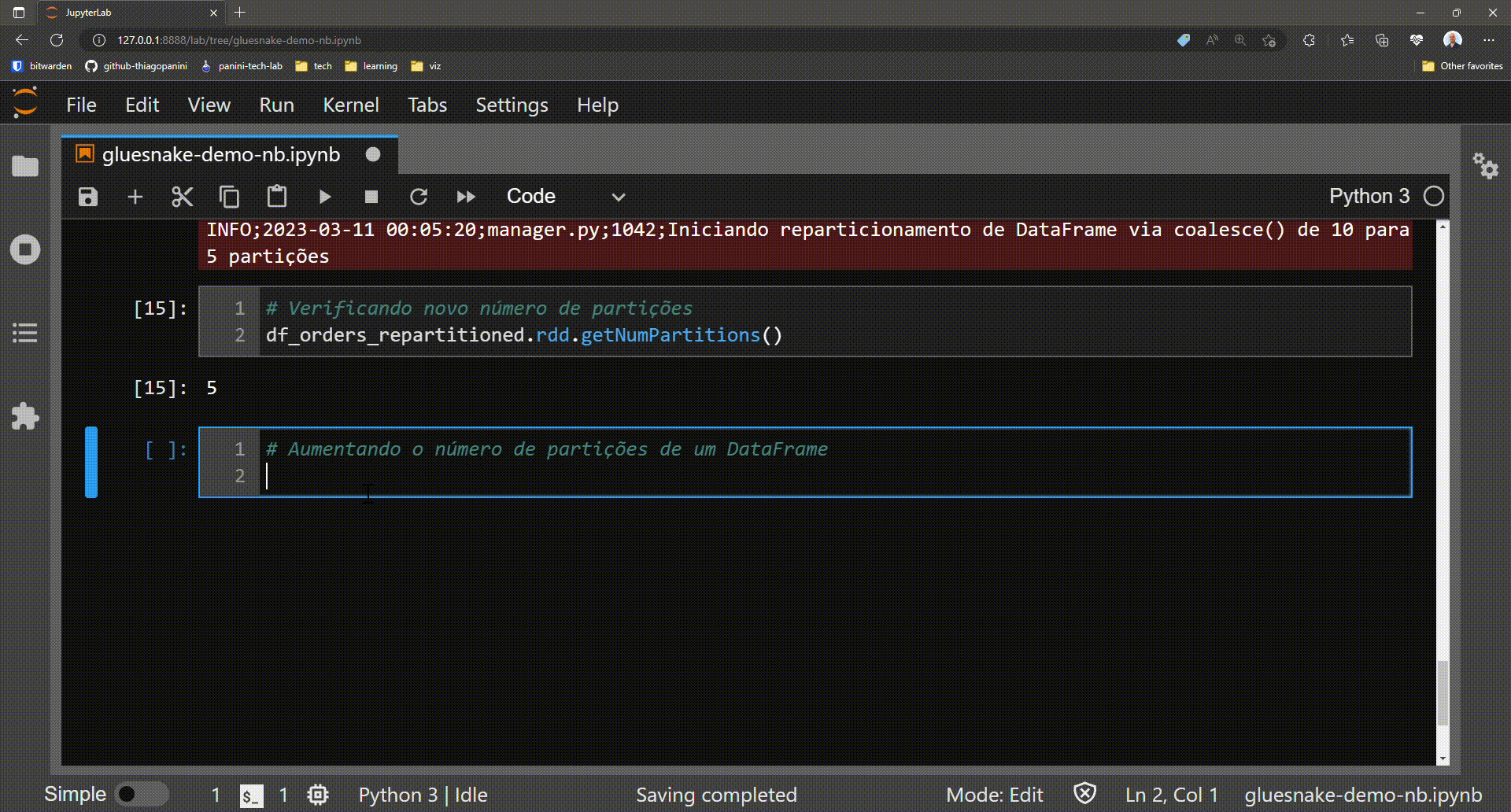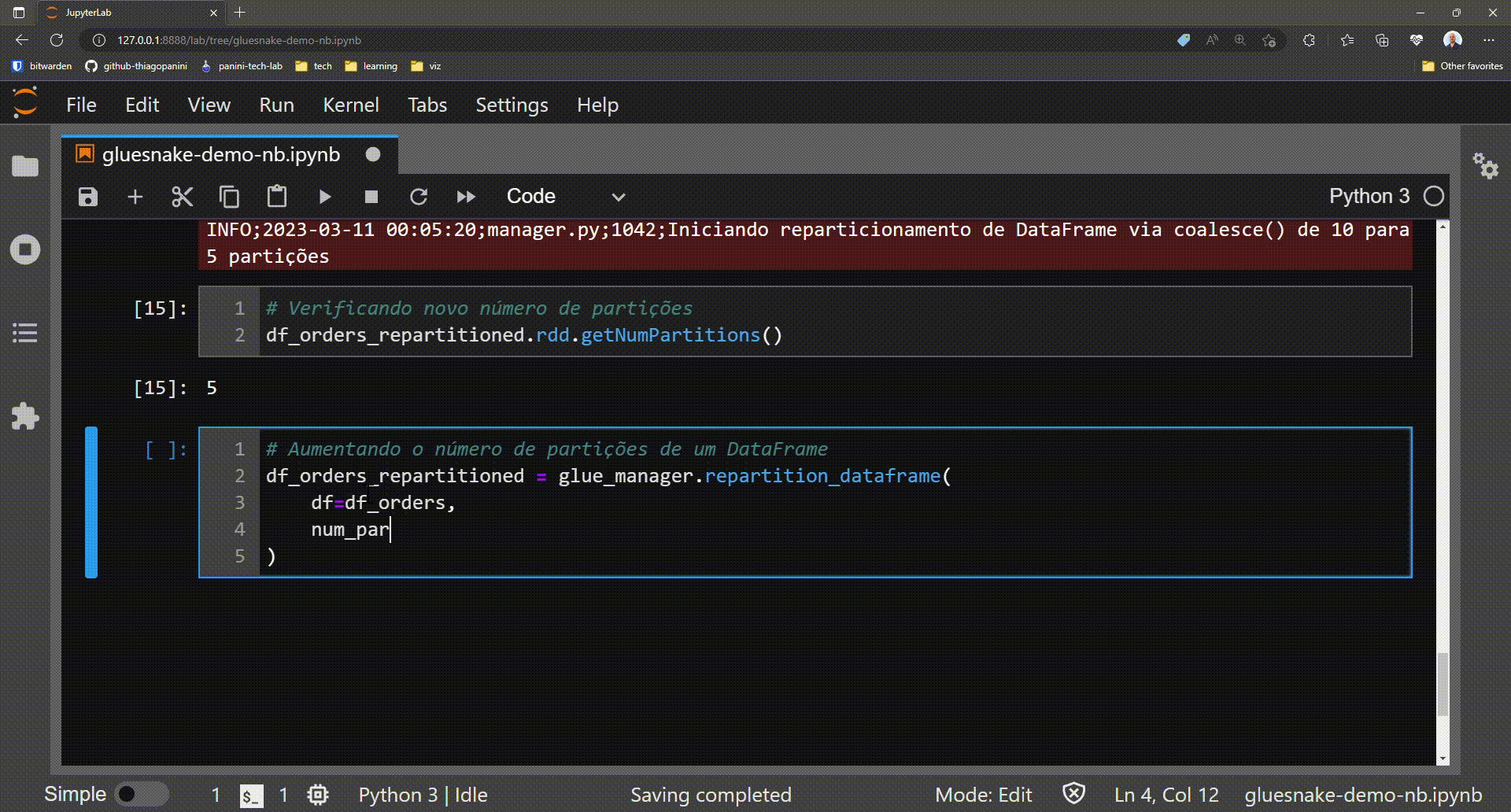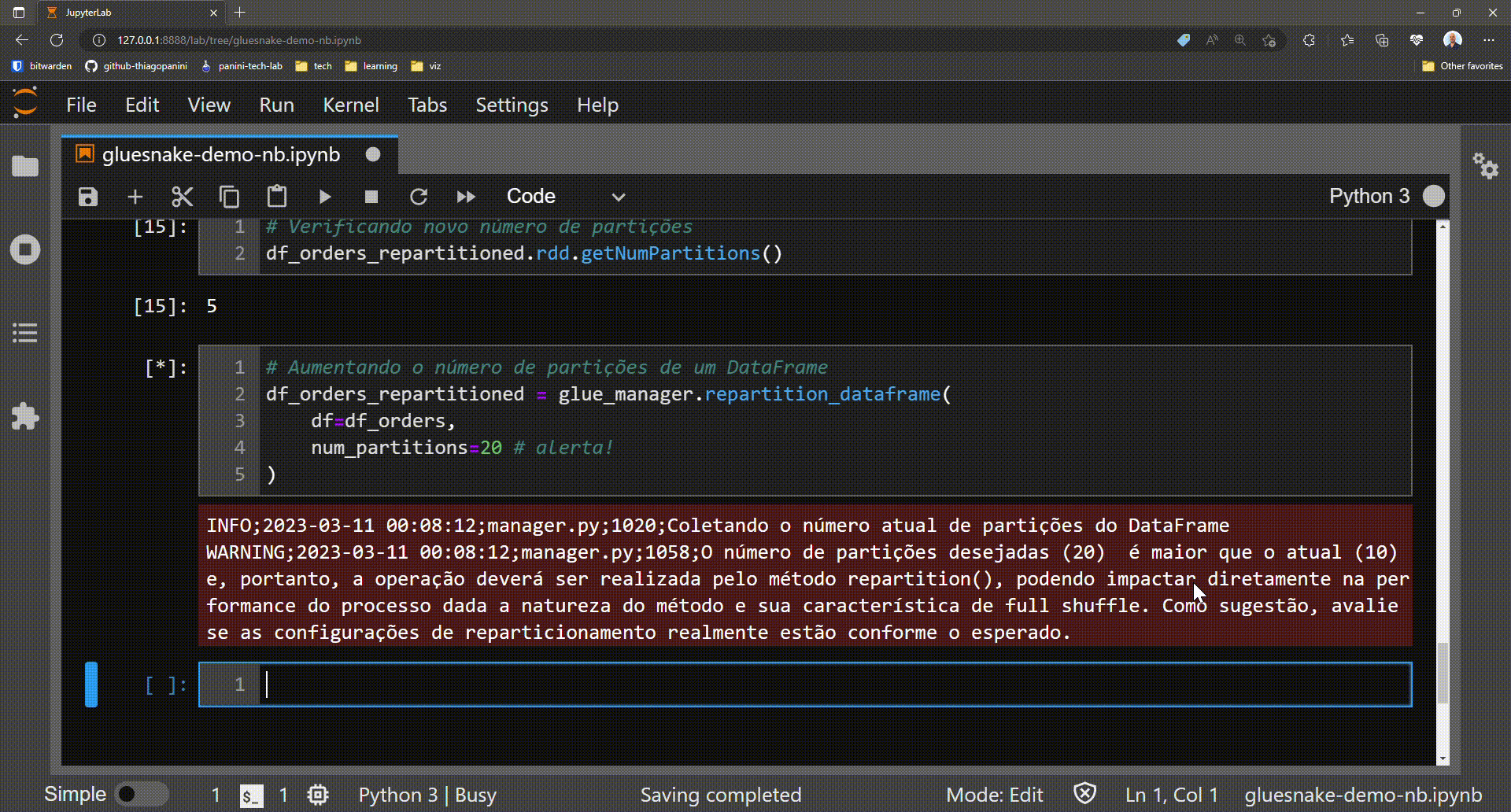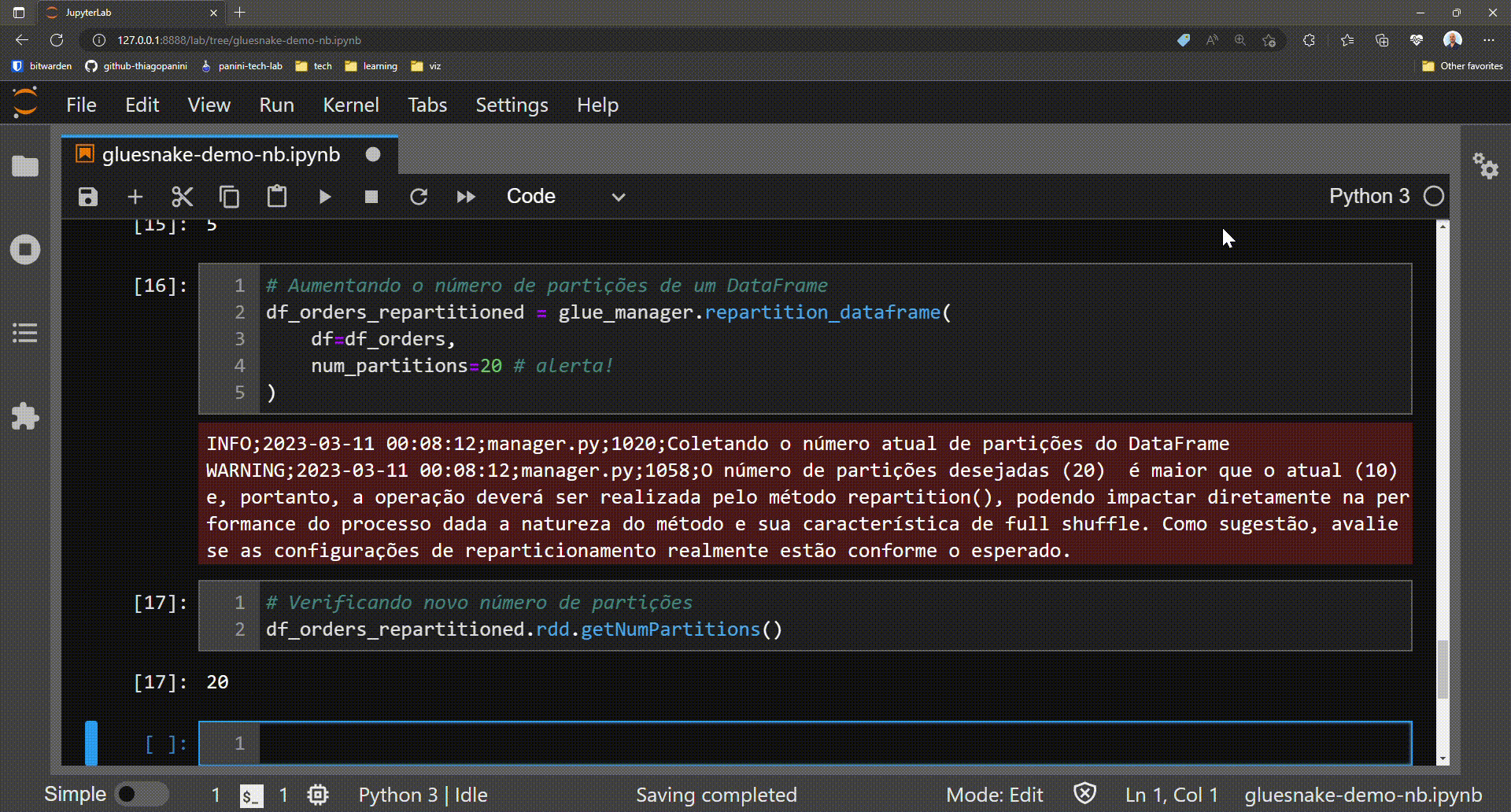
Optional: log warnings in case of increasing the number of partitions (full shuffle)
The method repartition_dataframe() works as follows:
- The current number of partitions in the target DataFrame is checked
-
The desired number of partitions passed as a parameter is checked
-
If the desired number is LESS than the current number, then the method
coalesce()is executed - If the desired number is GREATER than the current one, then the method
repartition()is executed
And it is precisely in this second scenario that a log alert is present to the user to make sure that this is actually the desired operation. This is because the method repartition() implies a full shuffle operation, and can dramatically increase the runtime of the Spark application.
For more details, check this Stack Overflow thread where both methods are compared and explained.
Writing and Cataloging Data¶
Finally, let's assume now that the sparksnake user has the mission of writing and cataloging the results of the encoded transformations. In Glue, natively, the methods needed to be called are:
.getSink().setCatalogInfo().writeFrame()
In the user's view, it would be easier to achieve the same goal with a single method call. For this, the method write_and_catalog_data() is present!
Writing data in S3 and cataloging in the Data Catalog
Demonstration:
Advantages and benefits:
- Abstração de diferentes métodos de escrita e catalogação em uma única chamada
- Possibilita uma maior organização da aplicação Spark desenvolvida
- Considera uma série de parametrizações para configurar especifidades na escrita dos dados
Code
# Definint output table URI in S3
s3_output_uri = "s3://some-bucket-name/some-table-name"
# Writing data and cataloging in Data Catalog
spark_manager.write_and_catalog_data(
df=df_payments_partitioned,
s3_table_uri=s3_table_uri,
output_database_name="ra8",
output_table_name="tbl_payments",
partition_name="anomesdia",
output_data_format="csv"
)
Learn more at GlueJobManager.write_and_catalog_data()